Une nouvelle version de HDInsight est sortie récemment, celle ci n’est encore qu’en Preview mais je l’ai essayé pour vous 😉
Dans cet article je vais dans un premier temps recenser les nouveautés de cette dernière version puis faire un focus sur HBase. Enfin nous verrons comment requêter des données provenant d’une table HBase en Hive !
HDInsight News
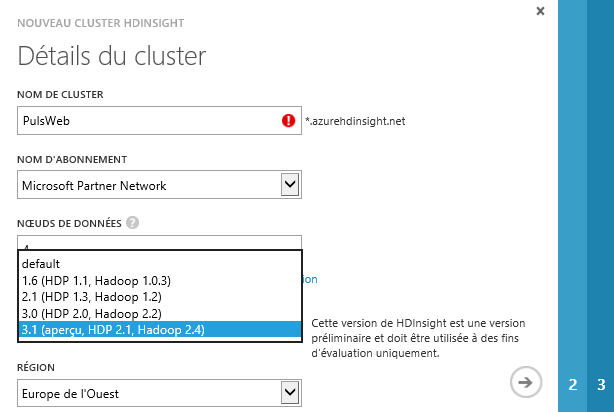
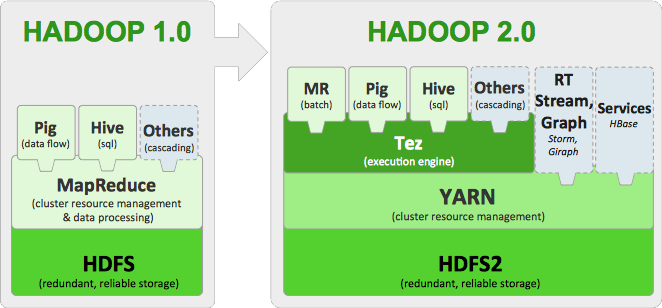
HDInsight 3.1 utilise une distribution Hadoop qui est basée sur la plateforme de données Hortonworks 2.1.
Plusieurs versions du cluster peuvent être déployées, chaque version se base sur une version de la plateforme Hortonworks HDP et se compose des composants suivants :
Voici quelques une des nouveautés de la version 3.1 :
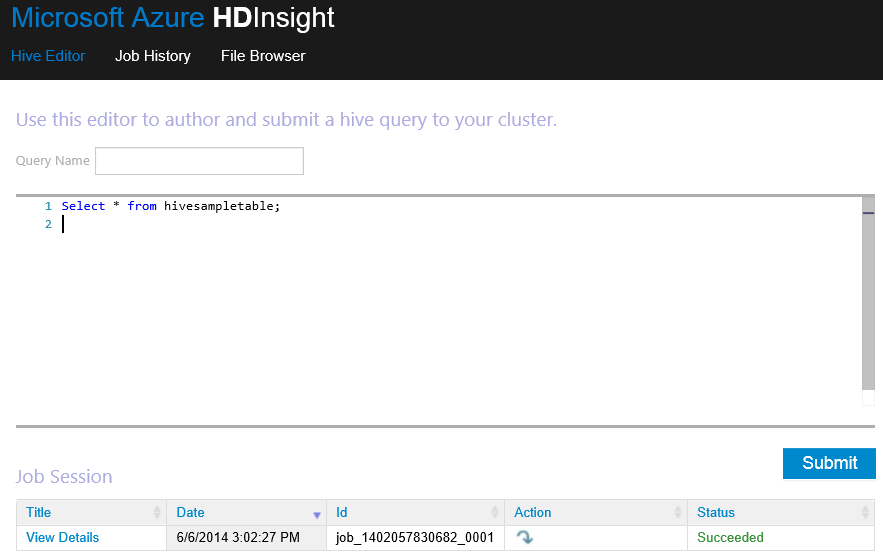
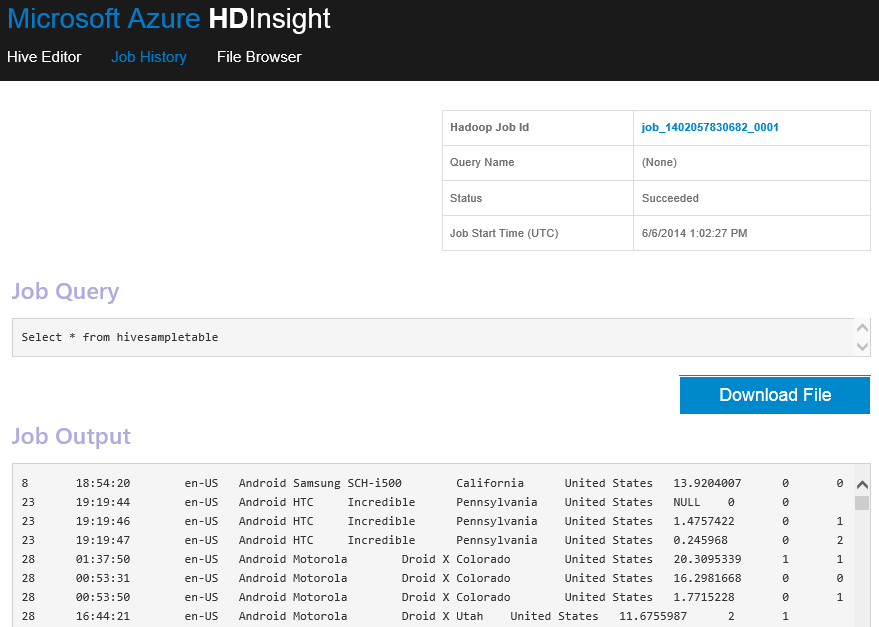
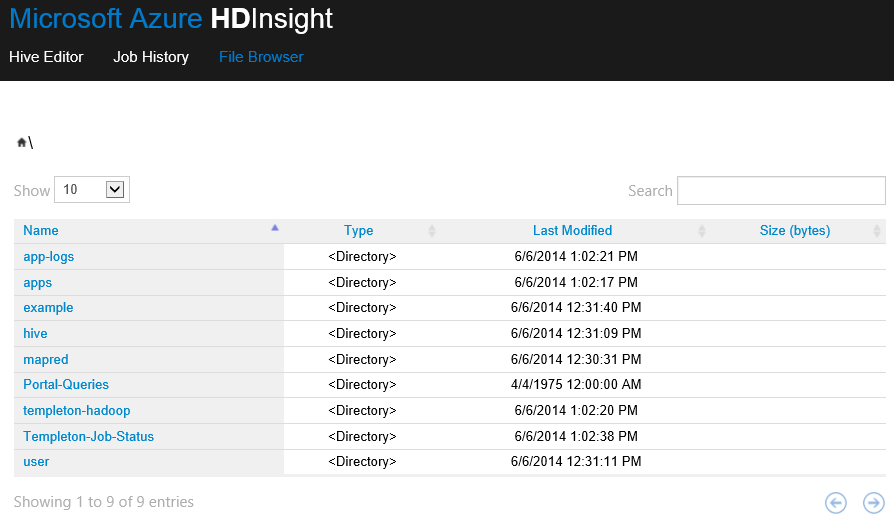
- Cluster Dashboard : Une nouvelle application Web est déployée sur votre cluster permettant d’exécuter des requêtes Hive, consultez les logs des taches et de parcourir l »Azure Blob storage. Cette une nouveauté que j’attendais particulièrement 🙂 Voici l’URL pour y accéder : https://CLUSTERNAME.azurehdinsight.net.
- Microsoft Avro Library : La bibliothèque met en œuvre le système de sérialisation de données Apache Avro pour l’environnement Microsoft.NET. Apache Avro fournit un format d’échange de données binaires compactes pour la sérialisation.
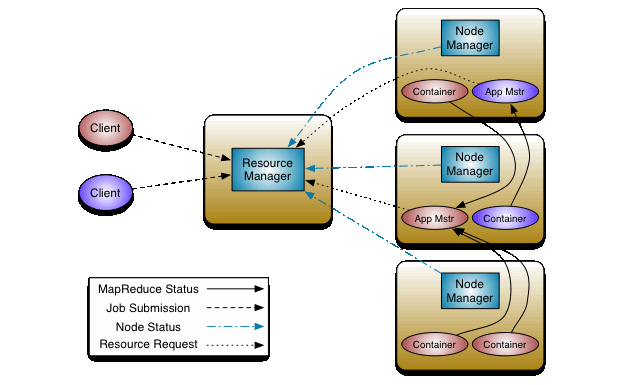
- YARN : « Yet Another Resource Negotiator » sépare la gestion des ressources et des composants de traitement:
- TEZ : C’est un Framework permettant de simplifier le traitement de données distribuées. Tez permet d’accélérer les traitements Pig et Hive en éliminant les tâches inutiles comme les lectures / écritures sur l’HDFS.
- Haute disponibilité : Un deuxième nœud principal (headnode) a été ajouté aux clusters permettant d’accroître la disponibilité du service.
- Hive : Les temps de réponse de requêtes Hive ont été largement améliorés (jusqu’à 40x) tout comme les taux de compression des données (jusqu’à 80%) grâce à l’utilisation du format Optimized Row Columnar (ORC).
HBase
![]()
HBase est un système de gestion de base de données non relationnelle distribué, écrit en Java, disposant d’un stockage structuré pour les grandes tables.
HBase elle est une base de données orientée colonnes, elle est inspirée des publications de Google sur BigTable.
HBase est un sous-projet d’Hadoop, un Framework d’architecture distribuée. La base de données HBase s’installe généralement sur le système de fichiers HDFS d’Hadoop pour faciliter la distribution, même si ce n’est pas obligatoire.
Pour information Mark Zuckerberg a annoncé le 15 Novembre 2010 que Facebook allait désormais utiliser HBase en remplacement de Cassandra.
Exemple d’utilisation
… À venir après quelques heures de tests et des vacances bien méritées :-p …
Integration of Hive and HBase

Comments are closed.