Une des problématiques récurrentes chez des clients concerne l’optimisation des procédures stockées. Elles sont utilisées à des fins de Reporting, pour standardiser du code T-SQL, pour améliorer les performances des applications, empêcher les injections SQL, …
Le sujet est tellement vaste que l’on pourrait en écrire un livre, je serai donc « non exhaustif » mais essayerai de mettre en évidence quelques problèmes rencontrés et leurs solutions, je réfuterai par la même occasion quelques mythes.
A partir d’exemples concrets, nous verrons dans un premier temps les bénéfices d’utiliser les procédures stockées plutôt que des requêtes Ad-hoc, nous ferons appel aux Extended Events pour afficher les évènements de recompilation et connaitre leurs causes, nous verrons les causes d’obsolescences de plan d’exécution mise en cache. Enfin nous optimiserons une même procédure en appliquant différentes techniques.
– L’article n’est pas un cours sur la façon de créer des procédures stockées
– L’article n’est pas un cours sur l’indexation, ni sur les statistiques
– Je ne parlerai pas des procédures stockées compilées nativement (Natively Compiled Stored Procedures)
Cela étant dit, allons-y !
Les procédures dans SQL Server
Une procédure est un groupe d’une ou de plusieurs instructions T-SQL enregistrées. Elles peuvent accepter des paramètres d’entrées et retourner ou non un ensemble de données, contenir des instructions effectuant des opérations sur une base de données, …
Pourquoi créer une procédure stockée ?
- Pour réduire le trafic réseau : Les commandes d’une procédure sont exécutées en un seul lot. Cela réduit le trafic réseau entre le serveur et le client car uniquement l’appel à la procédure est envoyé sur le réseau. Sans l’encapsulation de code fourni par une procédure, chaque ligne de code aurait transité sur le réseau.
- Pour des questions de sécurité : Les utilisateurs peuvent effectuer des opérations sur les objets de base de données par le biais d’une procédure malgré le fait qu’ils n’aient pas d’autorisations directes sur ces objets. Cela élimine la nécessité d’accorder des autorisations au niveau de l’objet et simplifie les couches de sécurité. Remarque : La clause EXECUTE AS peut être spécifiée dans l’instruction CREATE PROCEDURE pour permettre l’emprunt de l’identité d’un autre utilisateur. Pour plus d’information, je vous conseille le lien suivant : Managing Permissions with Stored Procedures in SQL Server.
- Pour ne pas avoir à répéter le même code : Les procédures permettent de centraliser les instructions et ainsi d’éliminer la redondance de code.
- Pour faciliter la maintenance : Les procédures offrent une couche d’abstraction aux objets sous-jacents d’une base de données.
- Pour améliorer les performances : Par défaut, les procédures sont compilées lors de leurs premières exécutions, un plan d’exécution est alors créé et pourra être réutilisé pour les exécutions suivantes. Du fait que le plan d’exécution est déjà créé, les prochaines exécutions devraient être plus rapides (« devraient » car nous verrons dans la suite de l’article que ça n’est pas toujours le cas!)
Voici le processus de traitement d’une procédure stockée jamais encore exécutée :
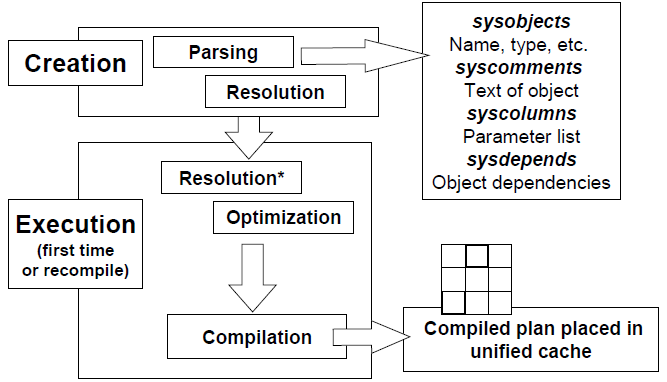
de Kimberly Tripp : http://www.sqlskills.com/blogs/kimberly/
Lors de la création d’une procédure stockée, SQL Server analyse la procédure pour s’assurer qu’il n’y ait pas d’erreurs syntaxiques. Une fois que la procédure est analysée avec succès, l’objet est placé dans les tables système (ajout des métadonnées).
Nous réfutons ici un premier mythe qui est le fait de penser que le plan d’exécution de la procédure est mis en cache lors de sa création.
Concernant la tache de résolution, elle est présente lors de la création de la procédure stockée et lors de sa première exécution. Lors de la création de la procédure, SQL Server va déterminer si les objets utilisés par celle ci existent et si tel est le cas il vérifiera les dépendances. Si par contre un des objets utilisés par la procédure n’existe pas, les références seront vérifiées que lors de la première exécution.
Remarque : Un plan est généré lorsqu’aucun plan n’existe déjà en cache, les plans ne sont jamais enregistrés sur le disque et peuvent être supprimés par différentes opérations (redémarrage de l’instance, la commande DBCC FREEPROCCACHE, certaines modifications de configuration de l’instance, la commande SP_RECOMPILE, …). D’autre part certaines opérations peuvent invalider le plan d’exécution (bien que l’objet reste en cache).
Quelques commandes pour avoir des informations sur une procédure stockée :
EXEC sp_helptext '[Schema].[ProcedureName]';
SELECT OBJECT_DEFINITION(OBJECT_ID('[Schema].[ProcedureName]')) AS [Object Definition];
SELECT
OBJECT_NAME([sm].[object_id]) AS [Object Name],
[sm].[definition] AS [Object Definition]
FROM [sys].[sql_modules] AS [sm];
Préambule
Dans la suite de l’article, nous travaillerons sur la base de données Adventure Works 2014 que vous pouvez télécharger sur Codeplex, vous pourrez ainsi rejouer les scripts.
Afin de faciliter la lecture des plans d’exécutions mises en cache, création de la procédure « ProcedurePlans » :
CREATE PROCEDURE [RCA_ProcedurePlans] AS
SET NOCOUNT ON;
SELECT
OBJECT_NAME(ps.object_id, ps.database_id) AS ProcedureName,
ps.execution_count AS ProcedureExecutes,
qs.plan_generation_num AS VersionOfPlan,
qs.execution_count AS ExecutionsOfCurrentPlan,
SUBSTRING(st.text, ( qs.statement_start_offset / 2 ) + 1,((CASE statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE qs.statement_end_offset END - qs.statement_start_offset ) / 2 ) + 1) AS StatementText,
qs.statement_start_offset AS offset,
qs.statement_end_offset AS offset_end,
qp.query_plan AS QueryPlanXML
FROM
sys.dm_exec_procedure_stats AS ps
JOIN sys.dm_exec_query_stats AS qs ON ps.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
WHERE
ps.database_id = DB_ID()
AND OBJECT_NAME(ps.object_id, ps.database_id) NOT IN (N'RCA_ProcedurePlans', N'RCA_RecompileEvents')
ORDER BY
ProcedureName,
qs.statement_start_offset;
Pour afficher les évènements de recompilation et leurs causes, nous allons utiliser la procédure suivante :
CREATE PROCEDURE [dbo].[RCA_RecompileEvents] AS
SET NOCOUNT ON;
SELECT
[event].[value]('(event/@name)[1]', 'VARCHAR(50)') AS [EventName],
DATEADD(hh, DATEDIFF(hh, GETUTCDATE(), CURRENT_TIMESTAMP),
[event].[value]('(event/@timestamp)[1]', 'DATETIME2')) AS [EventTime],
[event].[value]('(event/data[@name="recompile_cause"]/text)[1]', 'VARCHAR(255)') AS [RecompileCause],
OBJECT_NAME ([event].[value]('(event/data[@name="object_id"]/value)[1]', 'INT'),
[event].[value]('(event/data[@name="source_database_id"]/value)[1]', 'INT')) AS [ObjectName],
[event].[value]('(event/data[@name="offset"]/value)[1]', 'INT') AS [offset],
[event].[value]('(event/data[@name="offset_end"]/value)[1]', 'INT') AS [offset_end]
FROM (
SELECT [n].[query]('.') AS [event]
FROM (
SELECT CAST([target_data] AS XML) AS [target_data]
FROM [sys].[dm_xe_sessions] AS [s]
JOIN [sys].[dm_xe_session_targets] AS [t] ON [s].[address] = [t].[event_session_address]
WHERE [s].[name] = N'XE_RCA_Recompiles' AND [t].[target_name] = N'ring_buffer'
) AS [sub]
CROSS APPLY [target_data].[nodes]('RingBufferTarget/event') AS [q]([n])
) AS [tmp];
La précédente procédure se base sur les évènements étendus, voici comment démarrer une session :
USE [master];
GO
DECLARE @ExecString nvarchar(4000);
SELECT @ExecString = N'CREATE EVENT SESSION [XE_RCA_Recompiles] ON SERVER'
+ N' ADD EVENT sqlserver.sql_statement_recompile( '
+ N' WHERE ([package0].[equal_uint64]([source_database_id], ( '
+ CONVERT(VARCHAR(5), DB_ID(N'AdventureWorks2014'))
+ ' )) AND [object_type]=(8272)))'
+ ' ADD TARGET package0.ring_buffer'
+ ' WITH (MAX_MEMORY=4096 KB'
+ ' , MAX_DISPATCH_LATENCY=1 SECONDS)';
EXEC ( @ExecString );
ALTER EVENT SESSION [XE_RCA_Recompiles] ON SERVER STATE = START;
Pour supprimer les sessions en cours :
IF (SELECT COUNT(*) FROM [sys].[dm_xe_sessions] AS [xes] WHERE [xes].[name] = N'XE_RCA_Recompiles') = 1
BEGIN
ALTER EVENT SESSION [XE_RCA_Recompiles] ON SERVER STATE = STOP;
DROP EVENT SESSION [XE_RCA_Recompiles]
ON SERVER;
END;
Optimisation : Compilation
Dans ce chapitre nous allons utiliser les deux précédentes procédures afin d’illustrer la recompilation et l’invalidation des plans mise en cache. Créons dans un premier temps une procédure composée de deux requêtes T-SQL :
CREATE PROCEDURE [dbo].[RCA_StateProvince] ( @StateProvince INT = NULL ) AS SELECT PST.StateProvinceID, PST.StateProvinceCode, PST.CountryRegionCode, PST.Name FROM [Person].[StateProvince] PST WHERE StateProvinceID=@StateProvince; SELECT PAD.AddressLine1, PAD.AddressLine2, PAD.City, PAD.PostalCode FROM [Person].[Address] PAD WHERE PAD.StateProvinceID=@StateProvince;
Après une première exécution de la procédure, voici les plans d’exécution en cache et leurs plans :

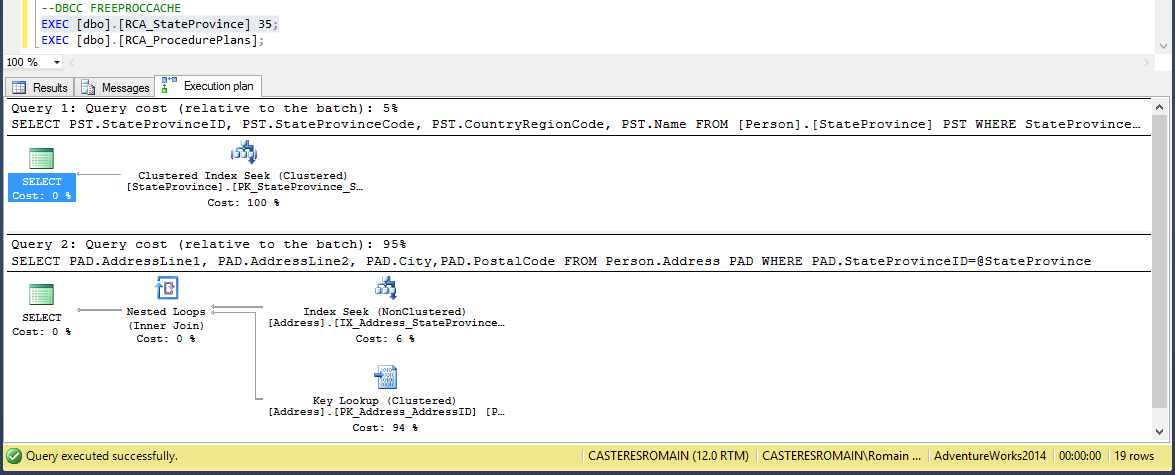
Le cache, vidé auparavant contient désormais le plan d’exécution des deux requêtes de la procédure [RCA_StateProvince] ayant étés exécutées une fois.
Créons maintenant un nouvel index afin d’optimiser les performances (suppression d’un index existant au profil d’un Covered Index) :
DROP INDEX [IX_Address_StateProvinceID] ON [Person].[Address]; GO CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID] ON [Person].[Address] ([StateProvinceID] ASC) INCLUDE ([AddressLine1],[AddressLine2],[City],[PostalCode]);
Best Practice : La clause INCLUDE ajoute les données au niveau le plus bas (feuille), plutôt que dans l’arbre d’index. Elle est généralement utilisée si la colonne n’est pas dans la clause WHERE / JOIN / GROUP BY / ORDER BY, mais seulement dans la liste des colonnes de la clause SELECT. Cela signifie qu’elle n’est pas vraiment utile pour les prédicats, tri, … La clause INCLUDE devrait avoir les champs dont vous avez besoin après qu’une ligne ait été trouvée, cela permet d’économiser des allers retour pour accéder à ces données.
Rééxecution des mêmes requêtes :
![]()
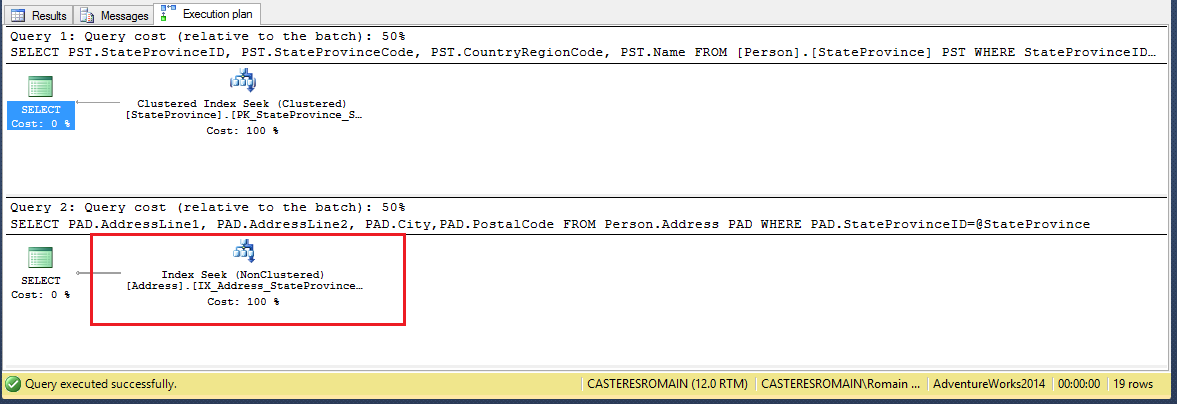
En cache, on peut voir que la première requête a été exécutée avec le même plan d’exécution tandis que l’exécution de la seconde requête a généré un nouveau plan d’exécution (VersionOfPlan). L’ancien plan d’exécution a été invalidé au profil d’un nouveau plan plus performant. Nous pouvons exécuter la procédure [RCA_RecompileEvents] pour en connaitre la cause (Offsets 482 à 746) :

D’autres actions peuvent causer l’obsolescence ou l’invalidation de plan d’exécution :
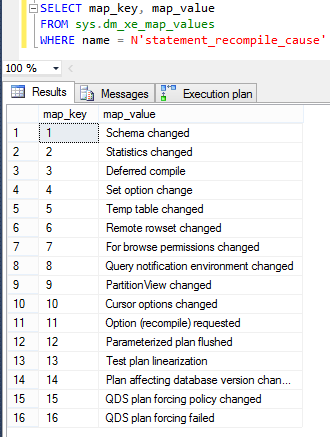
Informations : La réutilisation des plans peut être bénéfique lorsque différents paramètres passés à la procédure ne changent pas le plan optimal, SQL Server économise alors le temps de compilation et du temps CPU. La réutilisation des plans peut être néfaste lorsque les plans optimaux varient selon le jeu de paramètres. Si un plan d’exécution n’est pas bon, il est alors préférable de ne pas le sauvegarder, en effet le coût de la recompilation peut-être beaucoup moins impactant que le coût d’exécution d’un mauvais plan !
Optimisation : Conditions
Après la mise en place d’index (attention à ne pas trop en mettre !) la première optimisation rencontrée chez des clients est l’ajout de conditions dans une procédure.
Lorsqu’une procédure stockée est compilée ou recompilée, les valeurs des paramètres sont « snifés » (Parameter Sniffing) et utilisées pour l’estimation des cardinalités. Le plan d’exécution est optimisé par rapport à ces valeurs.
Prenons l’exemple suivant :
CREATE PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
IF @LastName NOT LIKE '%[_[[%]%'
SELECT *
FROM [Person].[Person]
WHERE [lastname] = @LastName;
ELSE
SELECT *
FROM [Person].[Person]
WHERE [LastName] LIKE @LastName;
La procédure [RCA_GetPerson] a été initialement créée pour accélérer les traitements de recherche d’information d’un employé en fonction de son nom et cela à l’aide d’une logique conditionnelle. Si le paramètre @LastName contient le caractère ‘%’ alors la première requête sera exécutée sinon ça sera la deuxième. Pensez vous que cela accélère les temps d’exécution ?
Faisons quelques tests :
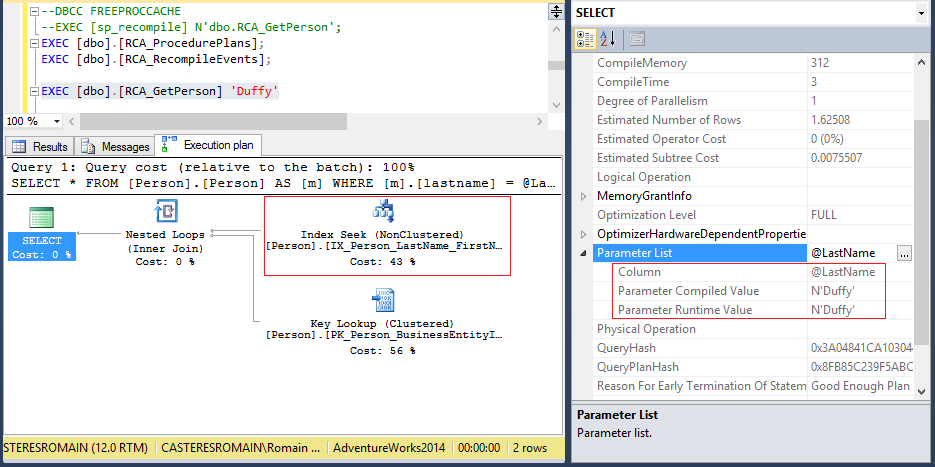
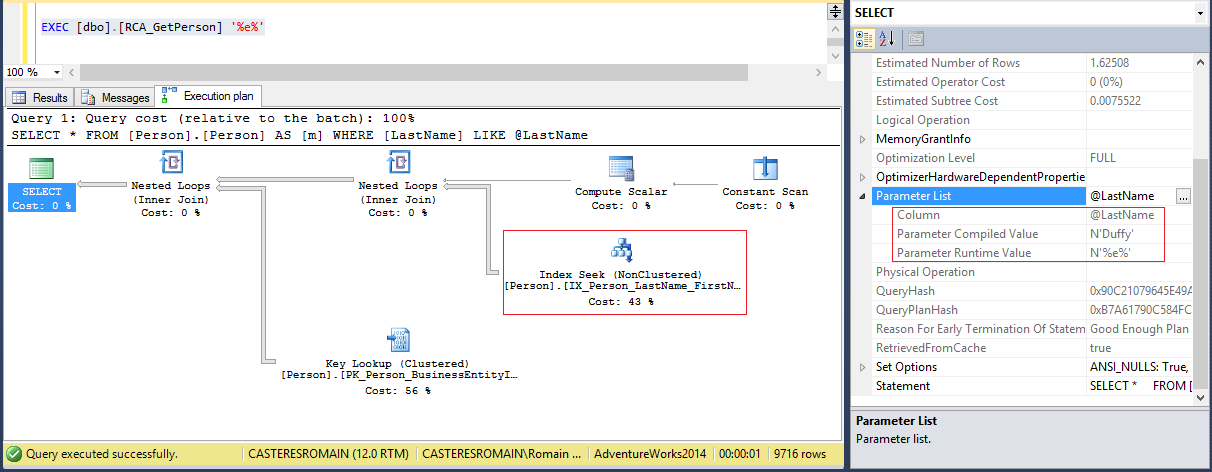
Voyez vous le problème ?
La première exécution de la procédure est hautement sélective, seules deux lignes ont été retournées contrairement à la seconde exécution qui retourne presque 10000 lignes. Le plan optimal de la seconde exécution a été construit à l’aide du paramètre « snifé » lors de la première exécution de la procédure, à savoir Duffy ! Le plan d’exécution n’est donc pas optimal, un Index Scan aurait été préférable plutôt qu’un Index Seek, et pour vous le confirmer :
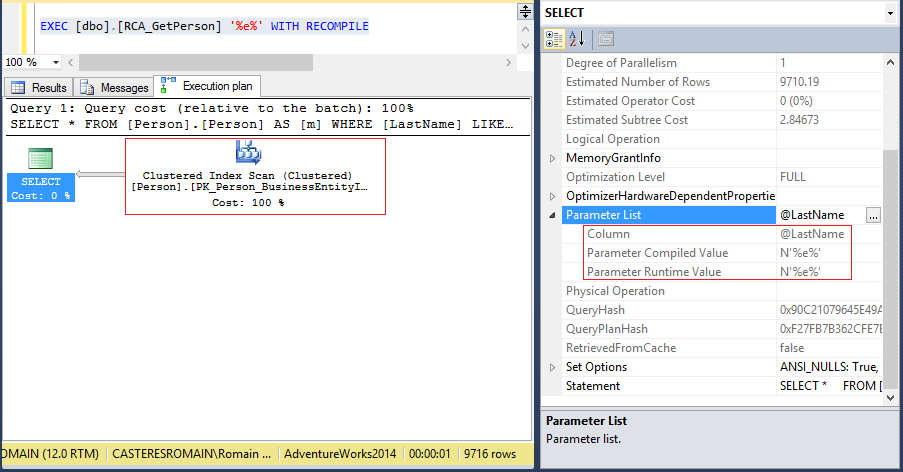
Nous réfutons ici un deuxième mythe qui est le fait de penser que l’ajout de ramifications, de conditions dans une procédure optimise celle ci.
Best Practice : L’option « WITH RECOMPILE », est à utiliser lors de tests, il recompile le plan uniquement pour cette exécution sans affecter le plan existant (en cache).
Informations : SQL Server ne saura optimiser l’instruction qu’au moment de son l’exécution. Tout comme les variables d’entrées, la ramification d’une instruction conditionnelle est inconnue. Le conditionnement n’influencera pas les performances comme vous le souhaiteriez, au contraire elle peut dégrader les performances de certaines requêtes comme dans cet exemple.
Optimisation : Modularisation
Plutôt que d’avoir de gros blocs dans les procédures stockées, il est préférable de la diviser en petits blocs, et ce, afin d’optimiser plus finement les transactions. La modularisation permet cela, au détriment de la maintenance d’un plus grand nombre d’objets.
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
IF @LastName NOT LIKE '%[_[[%]%'
EXEC [dbo].[RCA_GetPersonWithoutLike] @LastName;
ELSE
EXEC [dbo].[RCA_GetPersonWithLike] @LastName;
GO
CREATE PROCEDURE [dbo].[RCA_GetPersonWithLike] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
SELECT * FROM [Person].[Person]
WHERE [LastName] LIKE @LastName;
GO
CREATE PROCEDURE [dbo].[RCA_GetPersonWithoutLike] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
SELECT * FROM [Person].[Person]
WHERE [lastname] = @LastName;
La procédure « principale » porte le même nom, votre application n’aura donc pas être modifiée. Regardons les plans d’exécution :
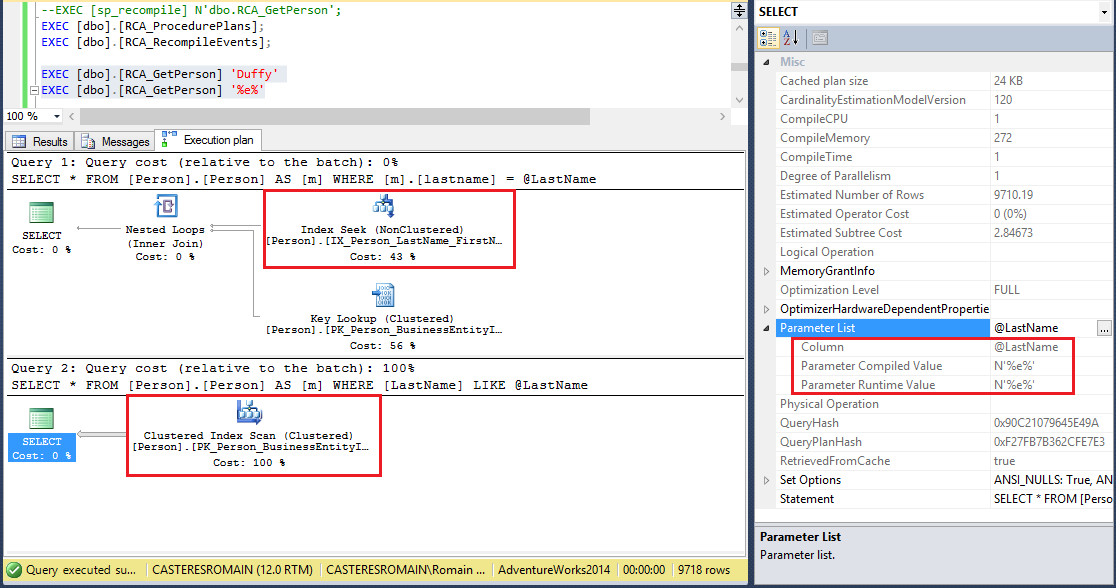
Si on regarde les plans d’exécution en cache, nous avons biens les deux procédures [RCA_GetPersonWithoutLike] et [RCA_GetPersonWithLike] :

Avons nous vraiment optimisé la procédure ?
Nous avons résolu le problème rencontré précédemment dans le chapitre Condition, à savoir quand est ce que mon plan est optimisé :
– Dans un conditionnement : lors de sa première exécution
– Dans des sous procédures : lors de l’exécution de chacune d’entre elles.
Une procédure ne sera pas optimisée tant qu’elle n’aura pas été appelée contrairement aux différents conditionnements optimisés par la première exécution de la procédure. Cependant le plan est t’il stable pour chacune de ces procédures ? Pas forcément, cela dépend du code et de la distribution des données !
Information : La modularisation permet à SQL Server d’optimiser plus finement les blocs, il n’entrera pas dans les sous procédures à moins qu’il doive l’exécuter.
Optimisation : Options
Nous avons vu jusqu’ici l’importance de la compilation des plans d’exécutions, il existe différentes options dans SQL Server pour « jouer » avec celle ci :
- Recompilation de la procédure :
EXEC [sp_recompile] N'Schema.MaProcedure'
- L’option « EXECUTE … WITH RECOMPILE » : force la recompilation d’une procédure lors de son exécution.
- L’option « RECOMPILE » : force la recompilation d’une procédure à chacune de ces exécutions.
- L’option « OPTIMIZE FOR … » : force la création d’un plan en cache à partir de la valeur passée, cela empêche le Sniffing de variable.
- L’option « OPTION (OPTIMIZE FOR UNKNOWN) » : force la création d’un plan en cache à partir d’une moyenne (distribution), cela empêche le Sniffing de variable.
Pour tester la variation d’un plan d’exécution :
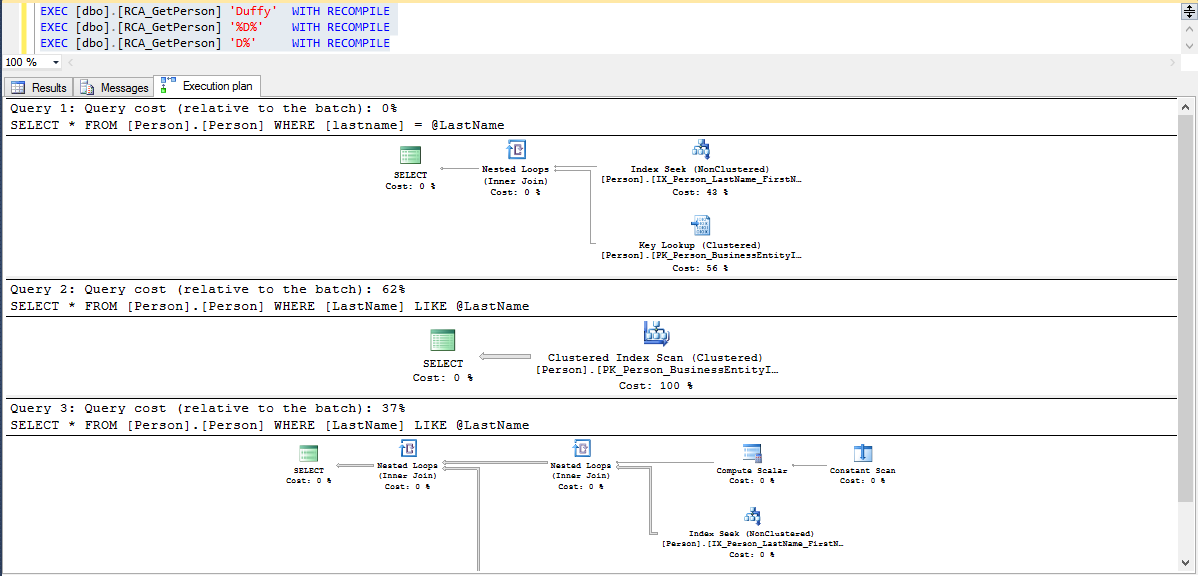
Modification de ma procédure initiale et ajout de l’option « WITH RECOMPILE » : Utilisation de l’option « WITH RECOMPILE »
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
)
WITH RECOMPILE AS
SET NOCOUNT ON;
IF @LastName NOT LIKE '%[_[[%]%'
SELECT *
FROM [Person].[Person]
WHERE [lastname] = @LastName;
ELSE
SELECT *
FROM [Person].[Person]
WHERE [LastName] LIKE @LastName;
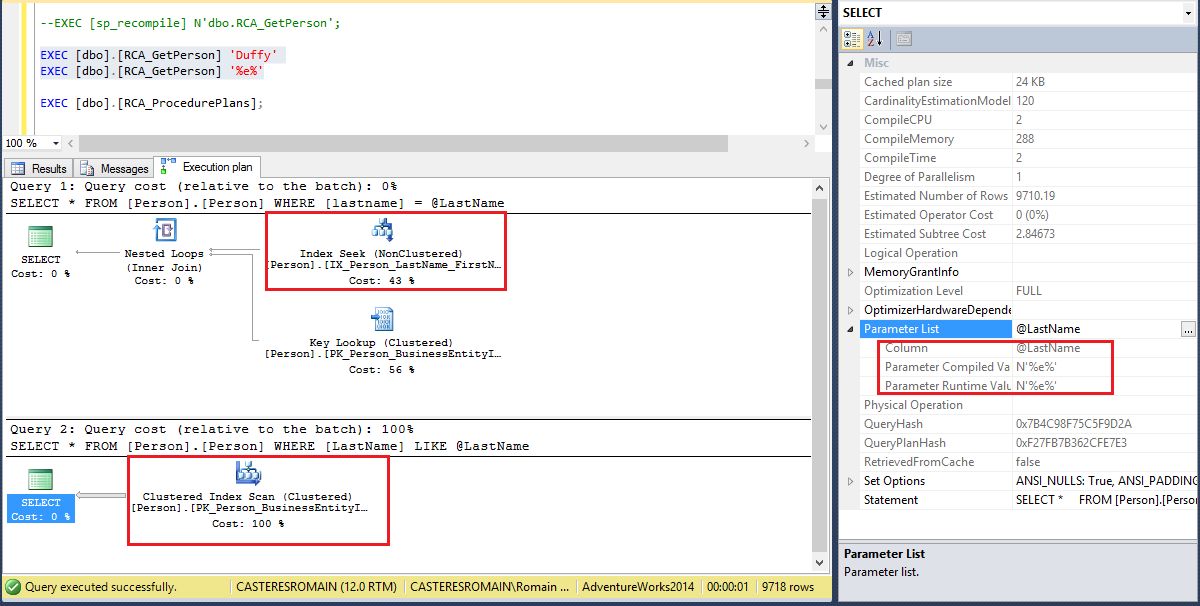
Les résultats sont similaires qu’avec la modularisation mais aucun plan d’exécution n’est sauvegardé en cache (EXEC [dbo].[RCA_ProcedurePlans];). Nous perdons donc l’un des avantages de l’utilisation des procédures stockées, à savoir la capacité ) rééxecuter des plans d’exécution optimisées.
Après avoir effectué quelques tests : analyse des paramètres passés à une procédure, analyse de la distribution des données de la table questionnée, … Il peut s’avérez utile de privilégier un plan d’exécution. L’option « OPTIMIZE FOR … » permet cela :
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
IF @LastName NOT LIKE '%[_[[%]%'
SELECT *
FROM [Person].[Person]
WHERE [lastname] = @LastName;
ELSE
SELECT *
FROM [Person].[Person]
WHERE [LastName] LIKE @LastName
OPTION (OPTIMIZE FOR (@LastName = '%D%'));
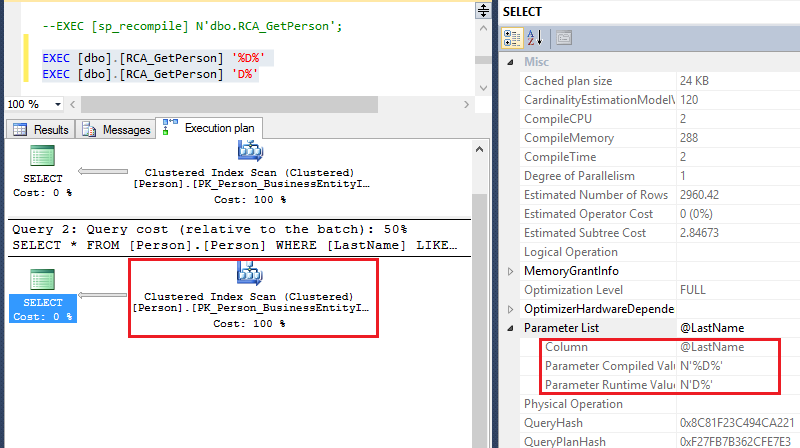
Après nous être aperçus que la plupart des requêtes ayant le caractère ‘%’ étaient plus performantes à l’aide d’un Index Scan, nous avons décidé de forcer son utilisation. Pour le paramètre ‘D%’ la procédure initiale effectuait un Index Seek, maintenant la deuxième branche de la procédure effectuera que des Index Scan.
Si par contre aucun pattern ne se dégage de l’analyse effectuée, l’option « OPTIMIZE FOR UNKNOWN » permet d’optimiser le plan en fonction d’une moyenne de distribution (utilisation de DBCC SHOW_STATISTICS) :
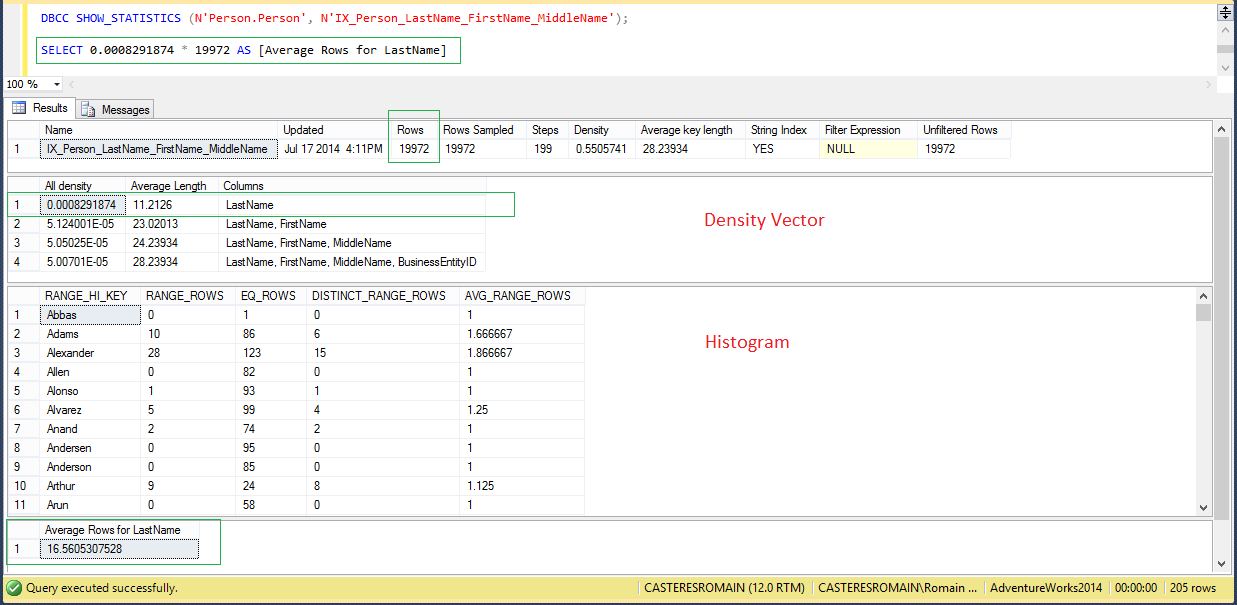
La moyenne de lignes retournées pour un nom de famille dans la table [Person] est de 16.56. Alors que le nom ‘Abba’ retourne une ligne, ‘Alexander’ en retourne 123.
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
IF @LastName NOT LIKE '%[_[[%]%'
SELECT *
FROM [Person].[Person]
WHERE [lastname] = @LastName
OPTION (OPTIMIZE FOR UNKNOWN);
ELSE
SELECT *
FROM [Person].[Person]
WHERE [LastName] LIKE @LastName
OPTION (OPTIMIZE FOR (@LastName = '%D%'));
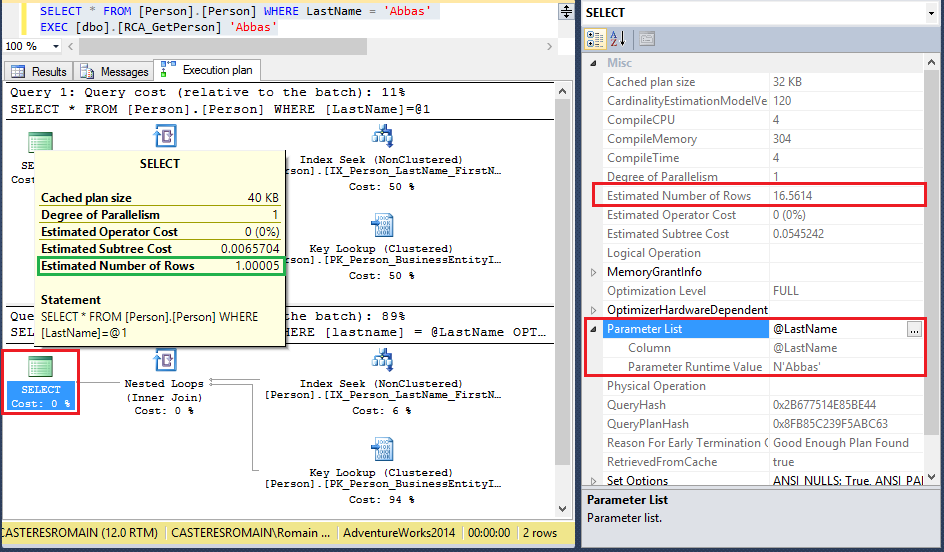
On retrouve en rouge les 16.56 lignes de la moyenne estimée. En vert, la requête utilise l’histogramme d’où le nombre estimé de lignes égal à 1.
Remarque : Plus les enregistrements seront proches de la moyenne, plus leurs requêtes seront efficientes, au contraire si une valeur est loin de la moyenne alors son exécution sera pénalisée.
Peut être que sans le savoir, vous utilisez déjà l’option OPTIMIZE FOR UNKNOWN, en effet SQL Server n’utilisera pas l’histogramme, mais le vecteur de densité lorsqu’une variable est modifiée dans la procédure :
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@LastName NVARCHAR (50)
) AS
SET NOCOUNT ON;
DECLARE @MyLastName AS NVARCHAR (50);
SET @MyLastName = @LastName
SELECT *
FROM [Person].[Person]
WHERE [lastname] = @MyLastName;
Informations :
– La recompilation n’est pas forcément une mauvaise pratique ! Si vous exécutez 15 fois une transaction et que vous obtenez 15 plans différents et qu’aucun pattern ne s’en dégage alors les options de recompilation peuvent s’avérer intéressantes.
– L’option « WITH RECOMPILE » ne s’applique qu’à la procédure « mère », les sous procédures ne seront pas recompilées !
– La procédure « sp_recompile » peut être utilisée sur une table, cela rendra obsolètes les plans en cache faisant appel à cette table.
– Si vous ne connaissez pas les données ou si vous ne voulez pas imposer une valeur pour optimiser le plan d’exécution d’une procédure et que la répartition des données est plutôt équilibrée, l’option « OPTIMIZE FOR UNKNOWN » peut s’avérer intéressante.
Optimisation 4 : Dynamique T-SQL
Rappelons avant tout qu’il ne faut JAMAIS utiliser « * » mais spécifier uniquement les colonnes nécessaires, pas comme dans mes précédents scripts T-SQL 😉
Voici la dernière technique d’optimisation que je présenterai dans cet article. Très souvent les procédures stockées ne prennent pas qu’un mais de multiples paramètres en entrée.
Cela nous amène à nous poser plusieurs questions :
– Que faire lorsqu’un des paramètres est NULL
– Que faire lorsque tous les paramètres sont NULL
– Quelles sont les combinaisons de paramètres à regrouper
– …
Plutôt que de longs discours, voici une des solutions que je préconise :
ALTER PROCEDURE [dbo].[RCA_GetPerson] (
@Person INT = NULL,
@Title NVARCHAR(8) = NULL,
@FirstName NVARCHAR (50) = NULL,
@LastName NVARCHAR (50) = NULL,
@EmailAddress NVARCHAR (50) = NULL,
@PhoneNumber NVARCHAR (25) = NULL
) AS
SET NOCOUNT ON;
IF (@Person IS NULL AND @Title IS NULL AND @FirstName IS NULL AND @LastName IS NULL AND @EmailAddress IS NULL AND @PhoneNumber IS NULL)
BEGIN
RAISERROR ('Vous devez fournir au moins un paramètre.', 16, -1);
RETURN;
END;
DECLARE @ExecString NVARCHAR(4000), @Recompile BIT = 1;
SELECT @ExecString = N'
SELECT
PRS.BusinessEntityID,
PRS.Title,
PRS.FirstName,
PRS.LastName,
Email.EmailAddress,
Phone.PhoneNumber
FROM Person.Person PRS
INNER JOIN Person.EmailAddress Email ON PRS.BusinessEntityID = Email.BusinessEntityID
INNER JOIN Person.PersonPhone Phone ON PRS.BusinessEntityID = Phone.BusinessEntityID
WHERE 1=1';
IF @Person IS NOT NULL
SELECT @ExecString = @ExecString + N' AND PRS.BusinessEntityID = @PKID';
IF @Title IS NOT NULL
SELECT @ExecString = @ExecString + N' AND PRS.Title = @Tle';
IF @FirstName IS NOT NULL
SELECT @ExecString = @ExecString + N' AND PRS.FirstName LIKE @FName';
IF @LastName IS NOT NULL
SELECT @ExecString = @ExecString + N' AND PRS.LastName LIKE @LName';
IF @EmailAddress IS NOT NULL
SELECT @ExecString = @ExecString + N' AND Email.EmailAddress LIKE @EAddress';
IF @PhoneNumber IS NOT NULL
SELECT @ExecString = @ExecString + N' AND Phone.PhoneNumber LIKE @PNumber';
IF (@Person IS NOT NULL)
SET @Recompile = 0 -- La condition est très sélective donc pas de recompilation nécessaire
IF (@Title IS NOT NULL)
SET @Recompile = 0
IF (@FirstName NOT LIKE '[%_?][%_?][%_?]%' AND @LastName NOT LIKE '[%_?][%_?][%_?]%') -- Au moins 3 caractères
SET @Recompile = 0
IF (@EmailAddress NOT LIKE '%[%_?]%') -- Aucun %
SET @Recompile = 0
IF @Recompile = 1
SELECT @ExecString = @ExecString + N' OPTION(RECOMPILE)';
SELECT @ExecString, @Person, @Title, @FirstName, @LastName, @EmailAddress, @PhoneNumber;
EXEC [sp_executesql] @ExecString
, N'@PKID INT, @Tle NVARCHAR(8), @FName NVARCHAR(50), @LName NVARCHAR(50), @EAddress NVARCHAR(50), @PNumber NVARCHAR(25)'
, @PKID = @Person
, @Tle = @Title
, @FName = @FirstName
, @LName = @LastName
, @EAddress = @EmailAddress
, @PNumber = @PhoneNumber;
GO
Pour valider la procédure, faisons quelques tests :
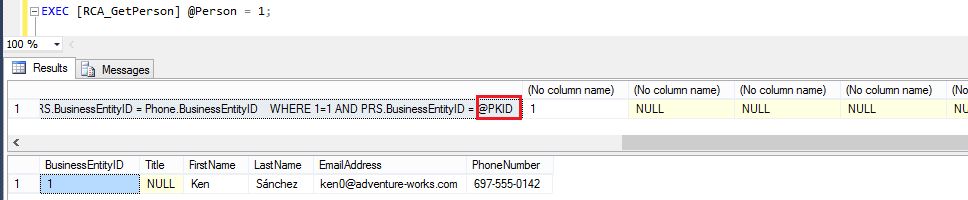
Après 3 exécutions de la procédure [RCA_GetPerson], regardons le cache des transactions :
SELECT
[st].[text],
[qs].[execution_count],
[qs].[statement_start_offset]
FROM [sys].[dm_exec_query_stats] AS [qs]
CROSS APPLY [sys].[dm_exec_sql_text] ([qs].[sql_handle]) AS [st]
CROSS APPLY [sys].[dm_exec_query_plan] ([qs].[plan_handle]) AS [qp]
WHERE
[st].[text] LIKE N'%1=1%'
AND [st].[text] NOT LIKE N'%dm_exec_sql_text%';

Le plan en cache a été réutilisé 3 fois, celui ci est optimal, car il utilise des Index Seek.
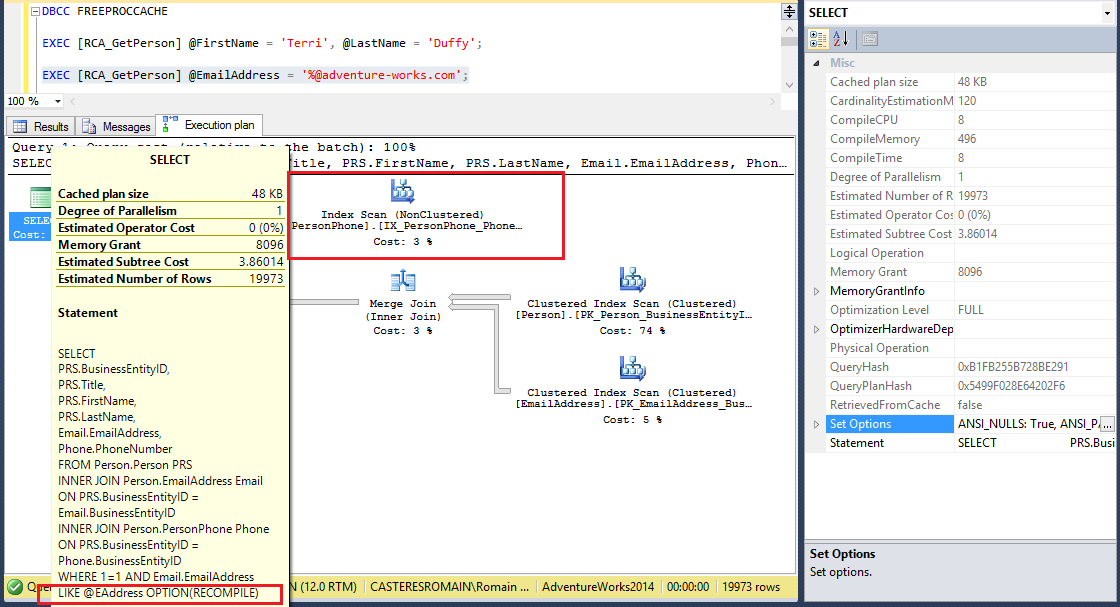
La recherche n’étant pas suffisamment sélective en vue du nombre d’emails correspondant, une recompilation du plan a été faite tout comme un Index Scan.
Après quelques tests, regardons une dernière fois le cache et vérifions le ré usage de certains plans :
EXEC [RCA_GetPerson] @Person = 1; EXEC [RCA_GetPerson] @FirstName = 'Terri', @LastName = 'Duffy'; EXEC [RCA_GetPerson] @EmailAddress = '%@adventure-works.com'; EXEC [RCA_GetPerson] @EmailAddress = 'terri0@adventure-works.com'; EXEC [RCA_GetPerson] @Title = 'Ms.'; EXEC [RCA_GetPerson] @PhoneNumber = '259-555-0112';

Sur les 15 exécutions: 11 ont été paramétrées, compilées, et réutilisées (Recompilation pour les autres non suffisamment sélective) ! Il y aura un plan d’exécution en cache par combinaisons sélectives.
Informations : Cette procédure est à titre d’exemple une option d’optimisation. Cependant, il n’existe pas de stratégie d’optimisation adéquate à tous les problèmes de performance. En effet, il faut utiliser les méthodes en fonction des données et des requêtes, mais savoir ce qui fonctionne et savoir tester est la clé pour effectuer de bonnes optimisations !
Compléments
Voici une liste (en vrac) de sujets non abordés dans l’article pouvant impacter les performances d’exécution d’une procédure :
- La commande « SET NOCOUNT ON » permet de gagner en performance puisque SQL Server ne renverra pas le nombre de lignes impacté par la transaction / procédure. Le paramètre de configuration suivant affecte cette valeur au serveur : « SP_CONFIGURE ‘user options’, 512 ».
- Utilise les index pour stabiliser les plans d’exécution d’une procédure.
- Attention aux types des données, utiliser la tache SSIS Data Profiling pour valider la pertinence des types.
- Lorsqu’une procédure stockée commence par SP_, SQL Server va d’abord chercher la procédure stockée dans la base Master avant de revenir sur la base donnée courante. Cela pénalise les performances.
- Plan Caching and Recompilation in SQL Server 2012 : SQL Server Technical Article.
- Utilisez la procédure stockée SP_EXECUTESQL au lieu de l’instruction EXECUTE pour l’exécution de requête dynamique (SET @Query = ‘SELECT * …’).
- Évitez les CURSEURS si possible.
A titre de conclusion, je dirais que le sujet est trop vaste pour être traité dans un article de blog. J’espère cependant vous avoir appris quelques astuces concernant l’optimisation de procédures stockées dans SQL Server !
PS : Je n’avais jamais autant passé de temps sur la rédaction d’un article 😮

Très intéressant … Merci Romain