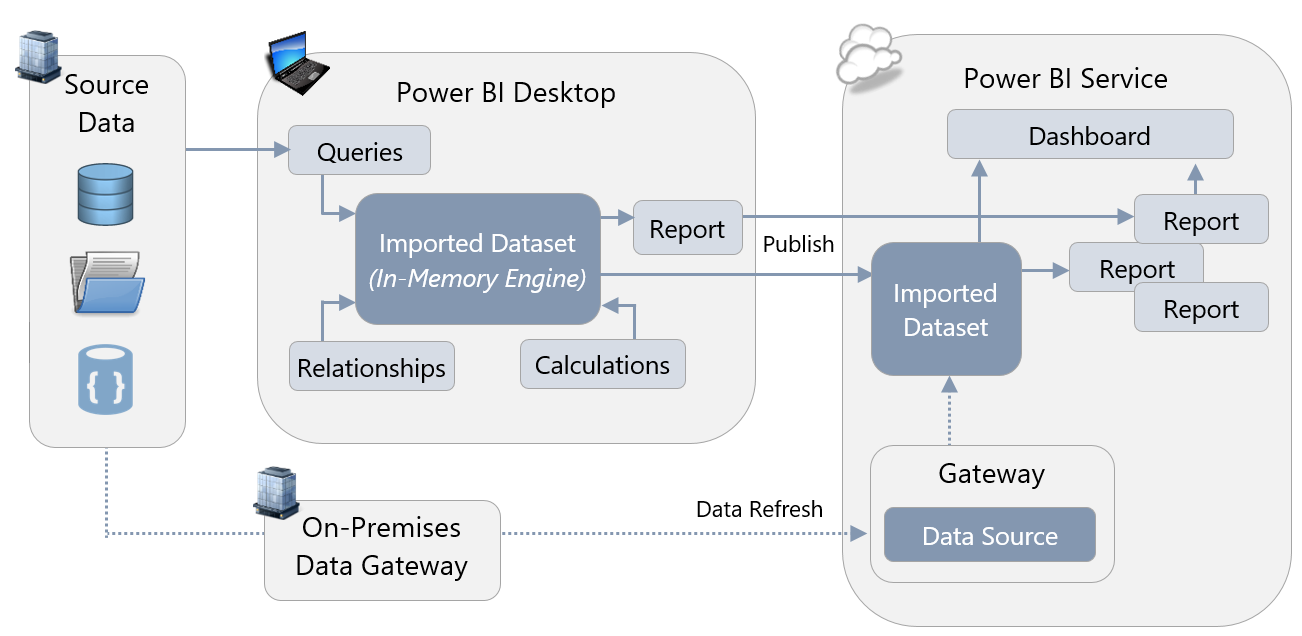
Introduction
Dans cet article je vais présenter certaines nouvelles fonctionnalités de l’On-Premise Data Gateway dans sa version entreprise (non personnelle) :

Pour rappel, la Passerelle de données locale permet de maintenir à jours dans le service Power BI, vos données On-Premise :
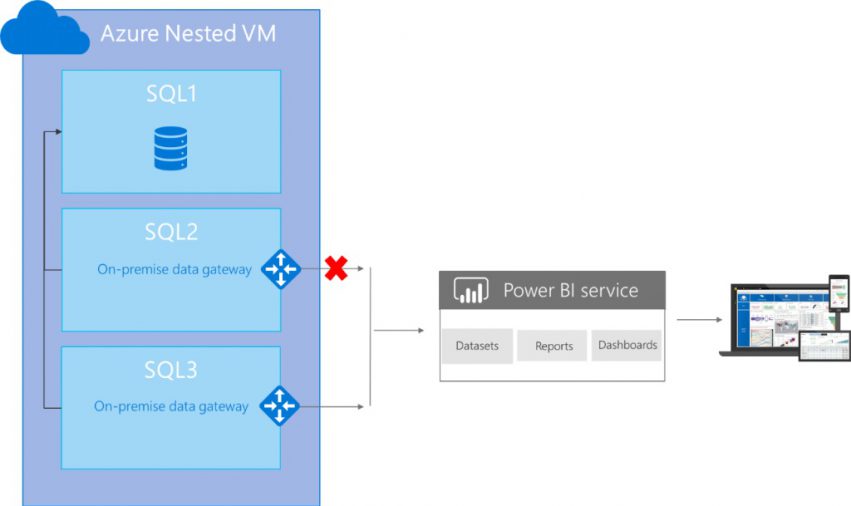
Exemple d’architecture :
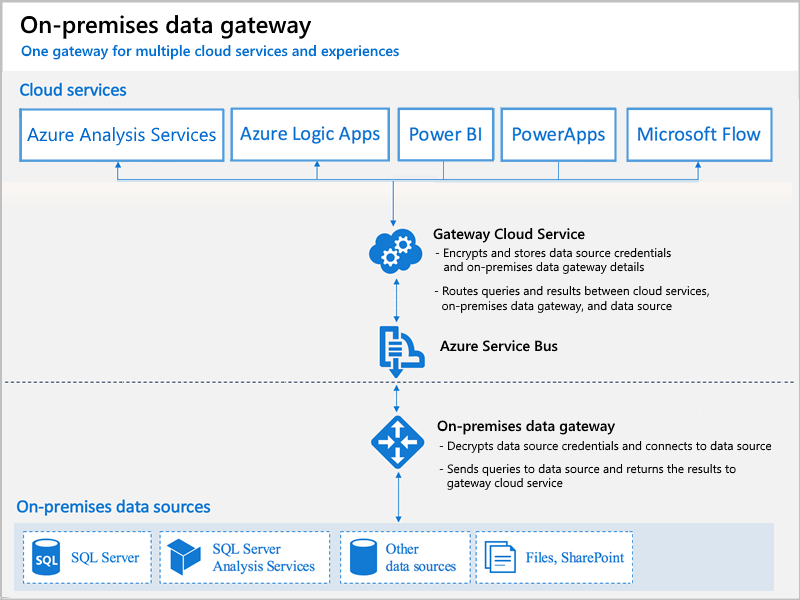
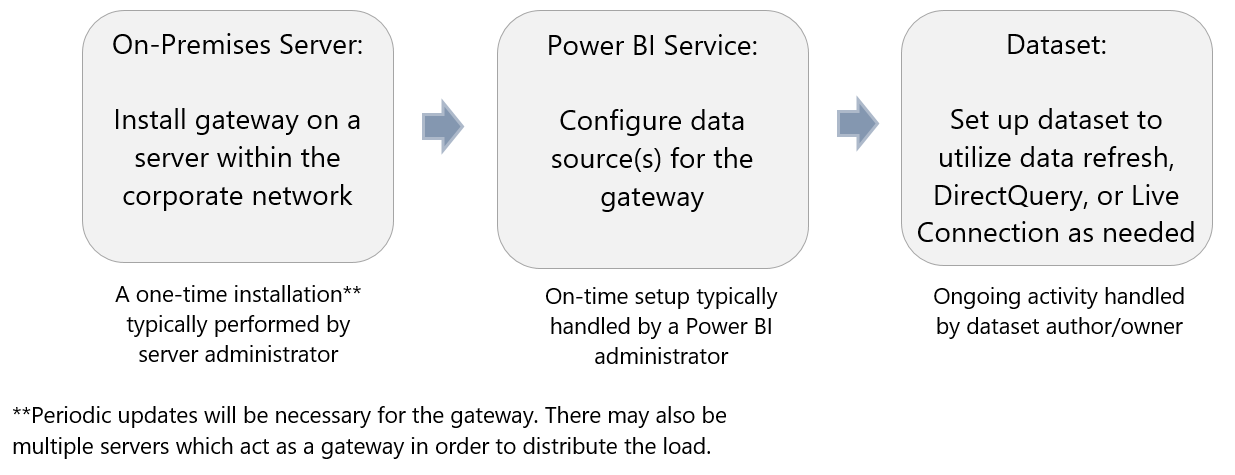
Information sur la passerelle :
– La passerelle inclut le moteur de Mashup (M, Power Query) afin d’effectuer les transformations On-Premise et d’envoyer uniquement le résultat des transformations dans le Cloud. On retrouve donc le moteur de Mashup dans la passerelle, dans Power BI Desktop et dans le service Power BI.
– Le transfert de données entre le cloud et la passerelle est sécurisé au moyen d’Azure Service Bus. Service Bus crée un canal sécurisé entre le cloud et votre serveur local via une connexion sortante sur la passerelle. Vous n’avez pas besoin d’ouvrir une connexion entrante sur votre pare-feu local.
– Il est désormais possible de travailler dans un même modèle avec des sources de données On-Premise et dans le cloud (combiné), pour cela la passerelle de données requiert l’activation explicite de l’option «Allow user’s cloud data sources to refresh through this gateway cluster».
– En fonction des transformations dans les requêtes le serveur hébergeant la passerelle peut être fortement sollicité, dans ce cas il est conseillé de repartir les sources de données sur plusieurs passerelles, d’utiliser la capacité de Load Balancing et / ou de les répartir sur plusieurs serveurs en fonction de leurs modes d’accès aux données (Import models vs. DirectQuery models). La passerelle n’est pas qu’un passe plat mais un vrai moteur de traitement de la donnée.
– Les administrateurs de passerelle peuvent contrôler le nombre de conteneurs qui s’exécutent simultanément sur la passerelle. Plus le nombre de conteneurs sera grand et plus les requêtes s’exécuteront simultanément via la passerelle. Pour modifier ce paramètre, dans “[Program Files]\On-premises data gateway\Microsoft.PowerBI.DataMovement.Pipeline.GatewayCore.dll.config”, trouver le paramètre “MashupDefaultPoolContainerMaxCount”. Après modification, il faudra redémarrer la passerelle. Attention, vous devrez trouver un bon équilibre entre l’efficacité obtenue en exécutant des requêtes simultanées et en optimisant les ressources du serveur que ces conteneurs utilisent. Un plafond recommandé pour le nombre maximal de conteneurs que vous pouvez utiliser est environ le double du nombre de cœurs dans votre processeur. La modification de cette valeur à 1 signifie que toutes les requêtes s’exécuteront séquentiellement, ce qui pourrait être intéressant pour des sources de données spécifiques qui ne prennent pas en charge ou ne fonctionnent pas correctement avec des demandes simultanées.
– Pour redémarrer la passerelle : « net stop PBIEgwService », « net start PBIEgwService ».
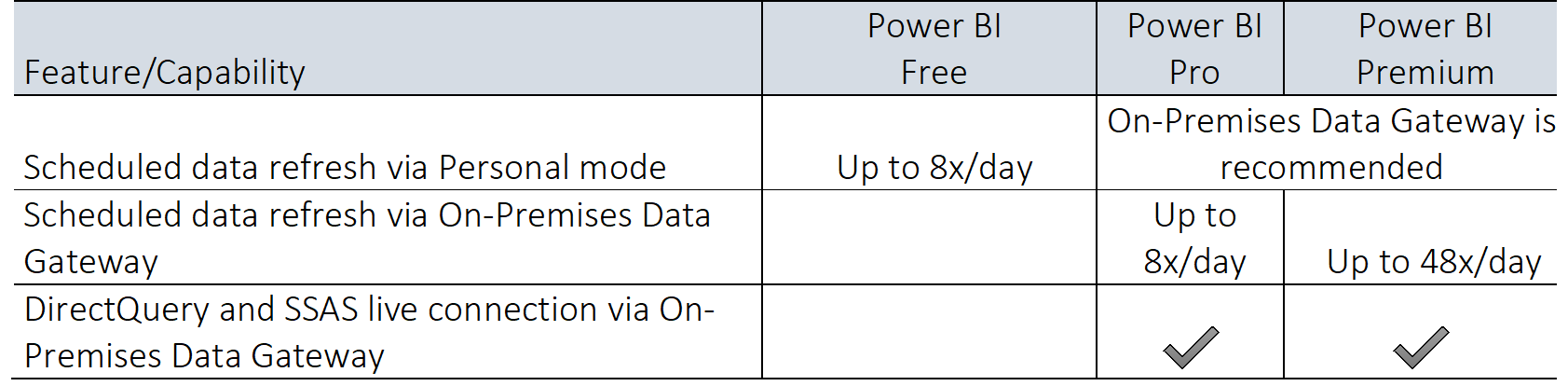
– Rafraichissement en fonction des licences :
Pour les besoins de la démonstration j’ai effectué les étapes suivantes :
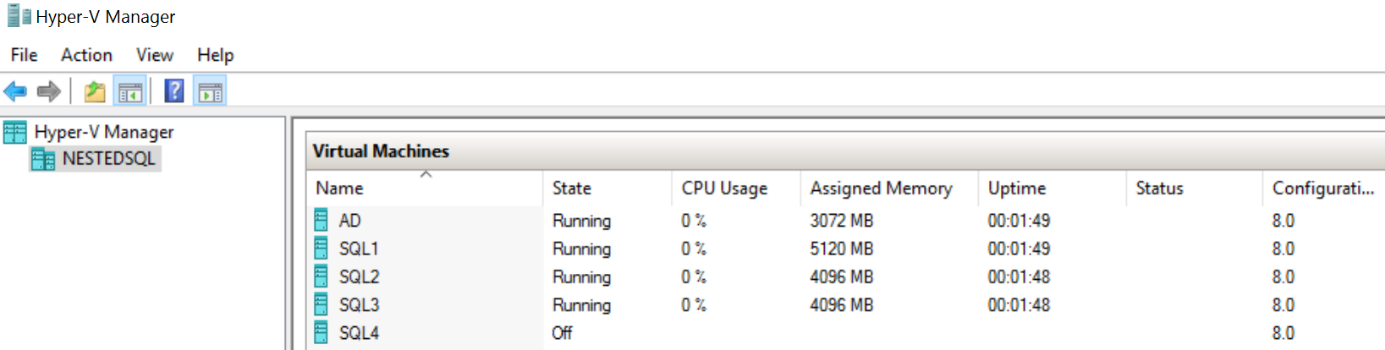
• Création d’un VM dans Azure permettant la virtualisation imbriquée (Nested Virtualization) : Standard D8s v3 (8 vcpus, 32 GB memory) https://docs.microsoft.com/fr-fr/azure/virtual-machines/windows/nested-virtualization
• Création de plusieurs VM à l’intérieur de la précédente via le service Hyper-V :
o AD : Pour la gestion de l’active Directory.
o SQL1 : Windows Server 2016, SQL Server 2017 (SQL1\SQL1), SSMS, SQL Operation Studio.
o SQL2 : Windows Server 2016, Power BI On-Premise Data Gateway.
o SQL3 : Windows Server 2016, Power BI On-Premise Data Gateway.
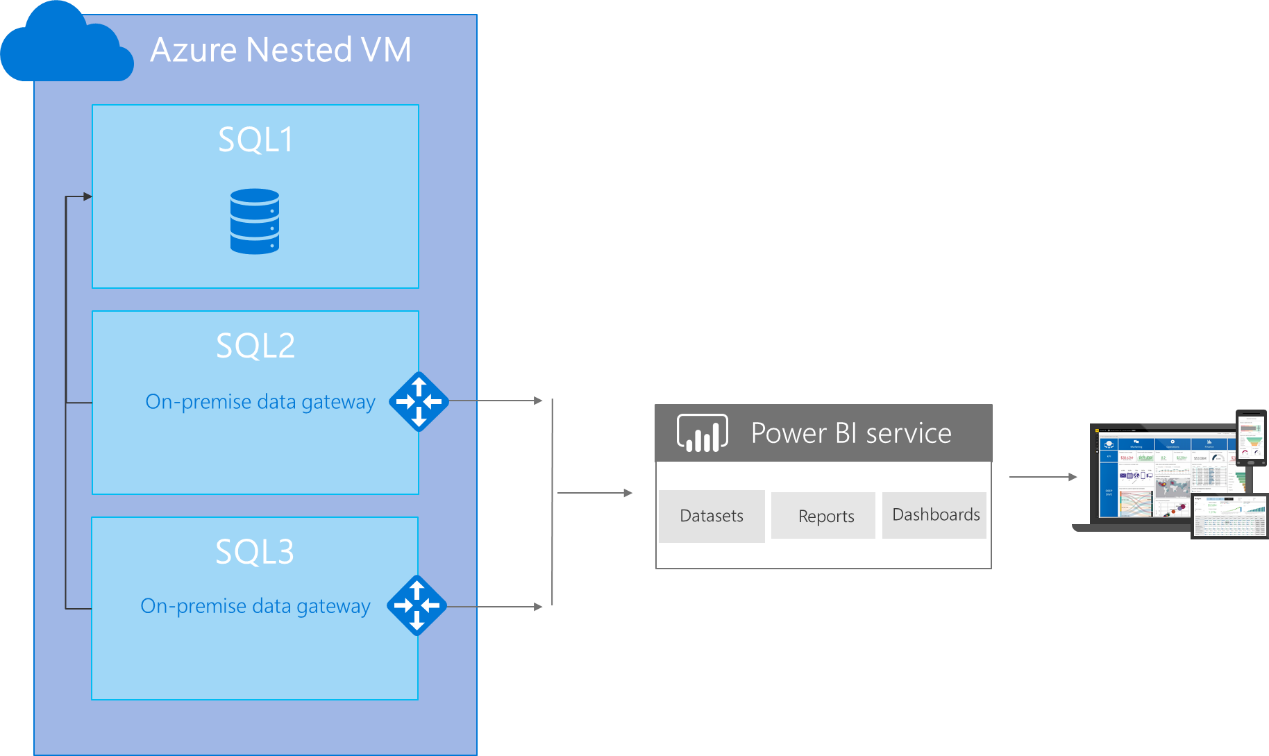
Voici l’architecture cible :
Pour télécharger la passerelle Power BI (numéro de Build : 14.16.6768.3) : https://go.microsoft.com/fwlink/?LinkId=820925&clcid=0x409
Haute Disponibilité
La haute disponibilité pour la passerelle de données permet aux administrateurs de regrouper plusieurs instances de passerelle, éliminant ainsi le point de défaillance unique et fournissant une infrastructure plus robuste et évolutive.
Le service Power BI utilise toujours la passerelle principale du cluster, sauf si elle n’est pas disponible. Dans ce cas, le service bascule vers la passerelle suivante du cluster, et ainsi de suite.
Étapes d’installation de la passerelle :
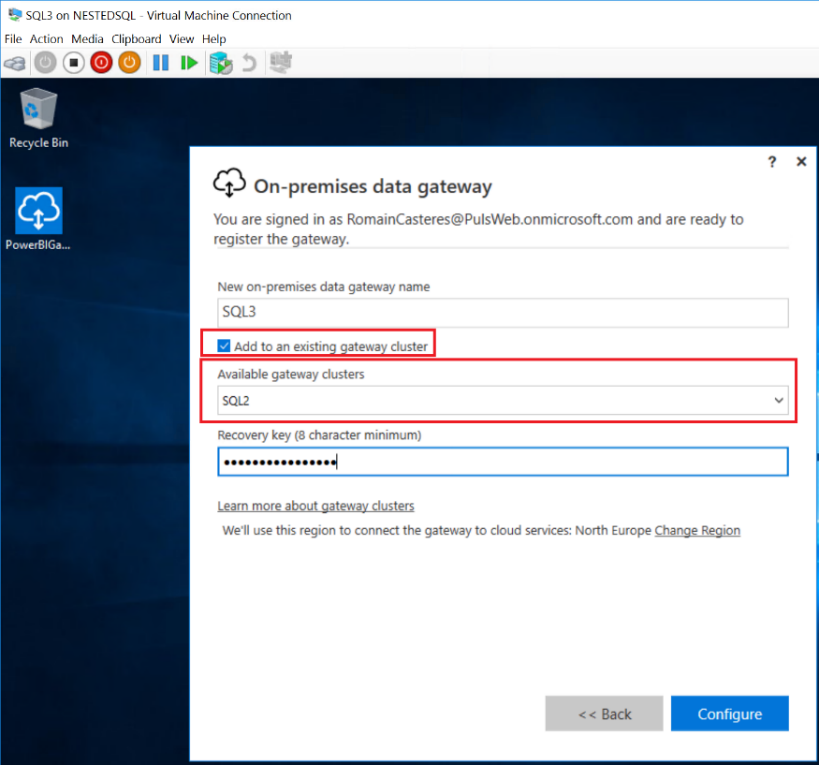
Lors de l’installation d’une nouvelle passerelle, les utilisateurs peuvent spécifier si l’instance de passerelle doit être ajoutée à un cluster existant ou à un nouveau. Les passerelles plus anciennes sont exposées dans leurs propres clusters, ce qui permet aux utilisateurs d’associer de nouvelles instances de passerelle à celles existantes ou de créer de nouveaux clusters.
Configuration :
1. Installation de la passerelle sur la VM SQL1
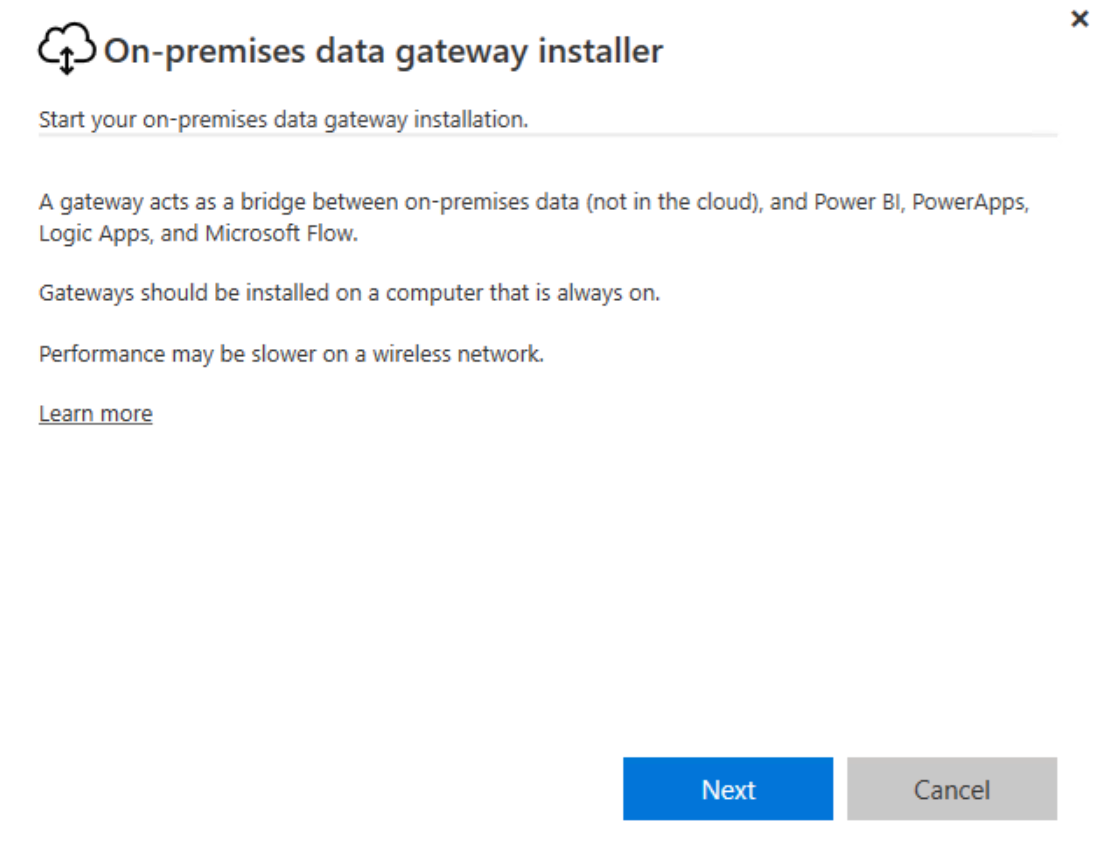
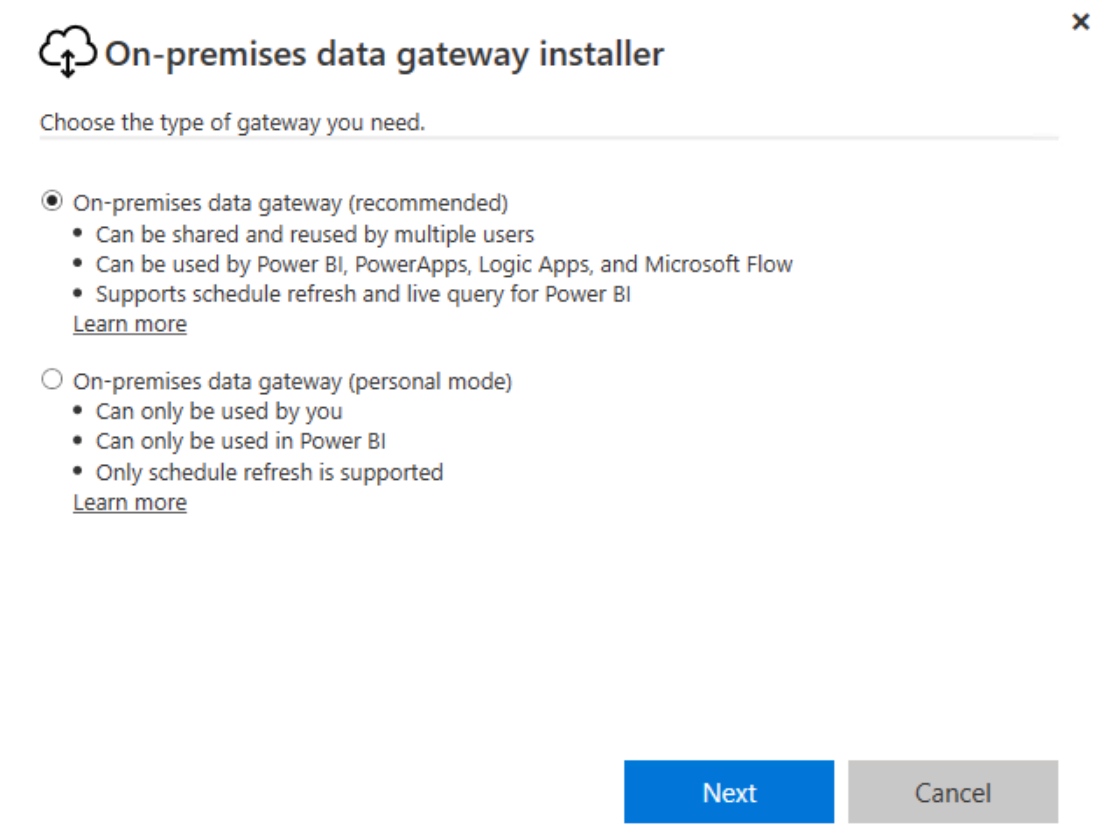
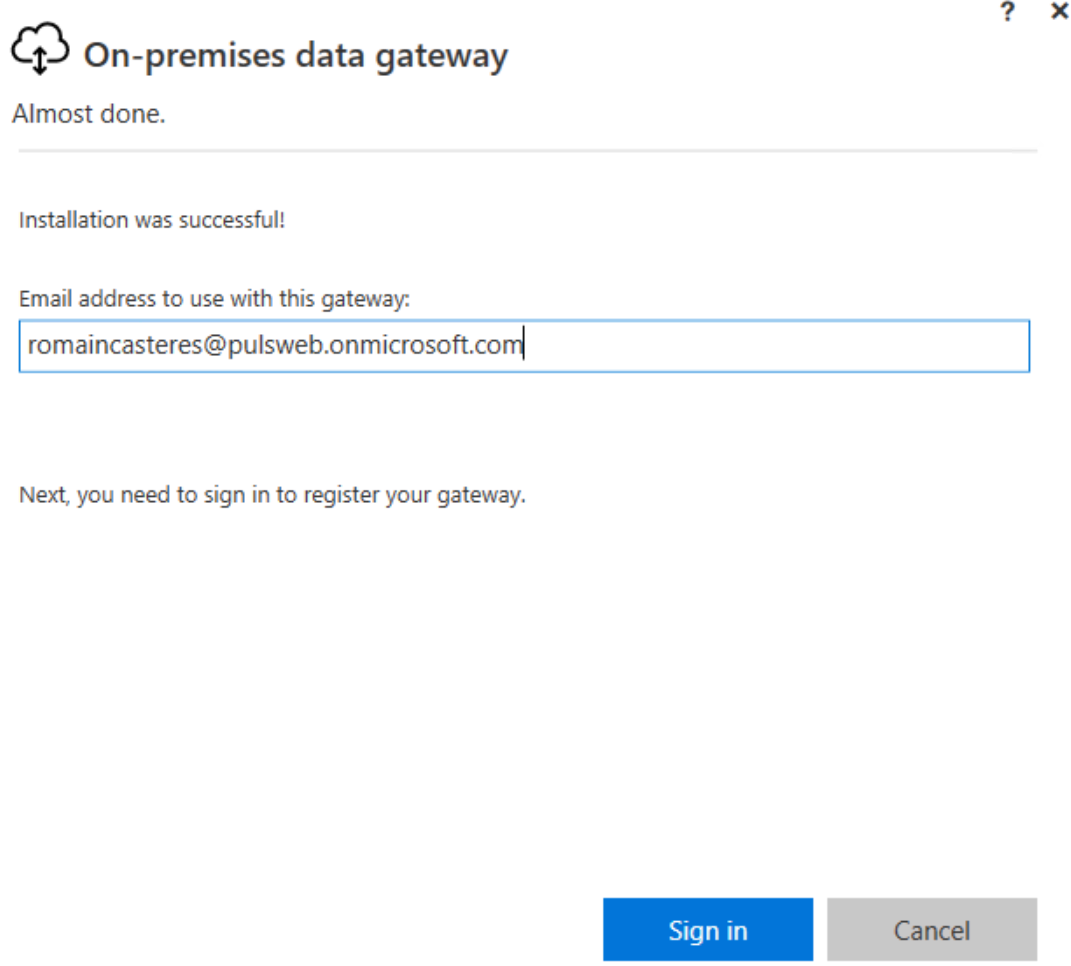
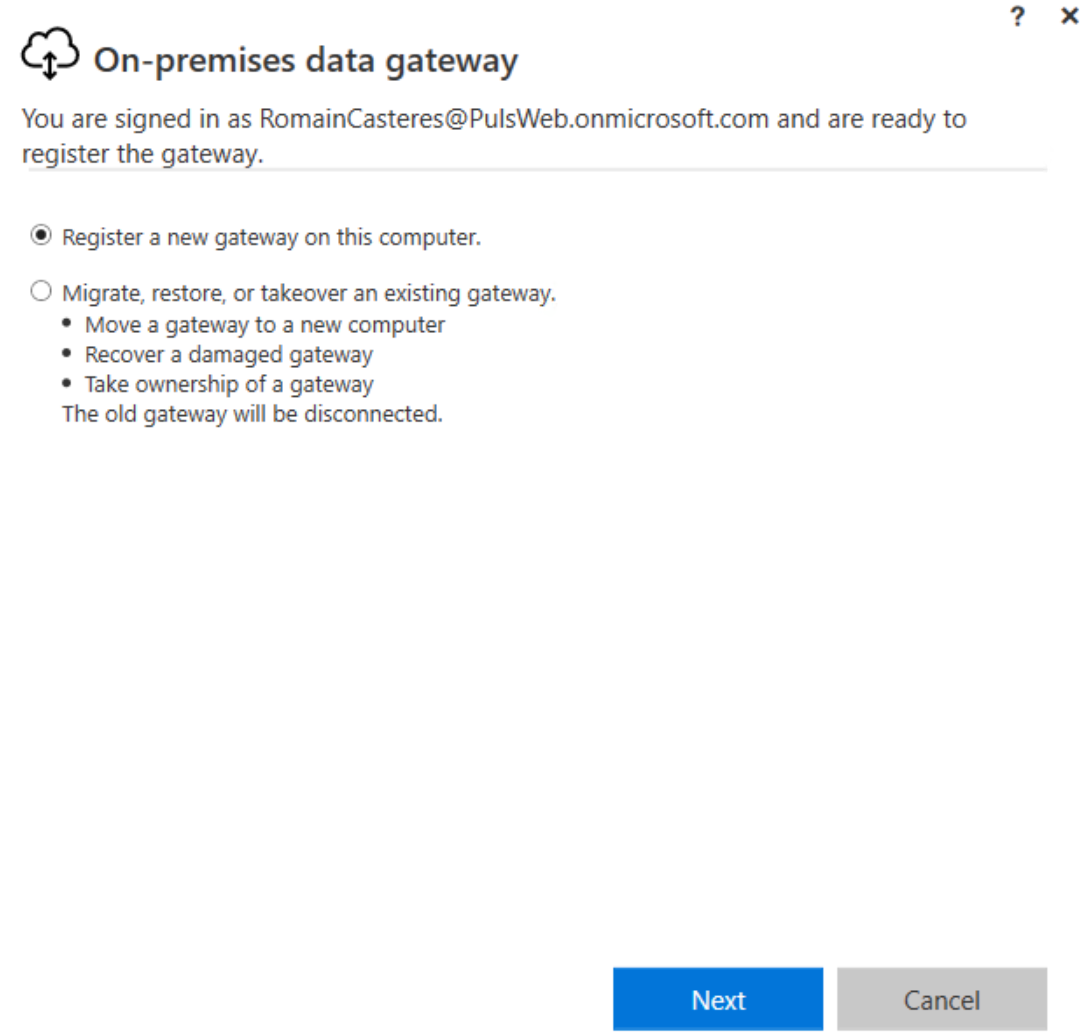
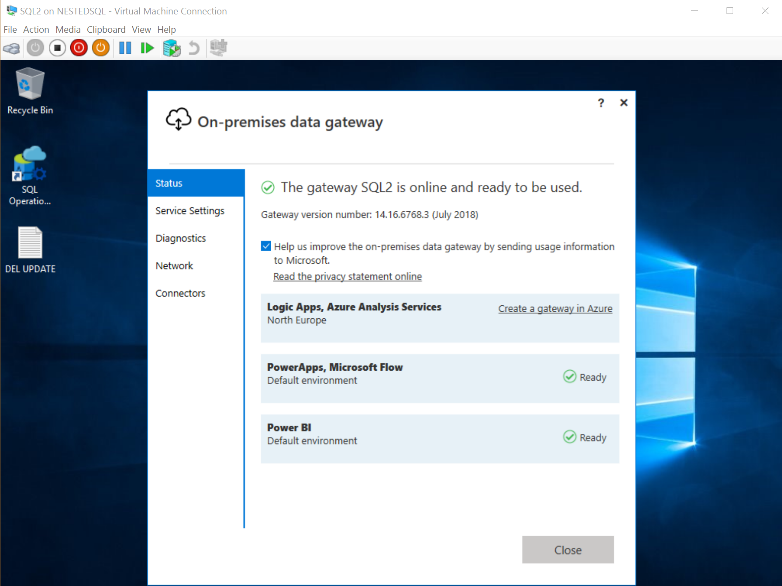
2. Installation de la passerelle sur la VM SQL2 en Cluster
3. Ajout d’une source de données à l’instance SQL1\SQL1

4. Création d’un rapport Power BI en Direct Query sur la base de données AdventureworksDW2016CTP3 de l’instance SQL1\SQL1 et publication de celui-ci dans le service Power BI.
5. Configuration de la source de données en utilisant la passerelle

Validation : Arrêt de la VM SQL2 et test d’accès aux données
1. 1ere requête en Direct Query sur le Gateway Cluster -> HostName SQL2
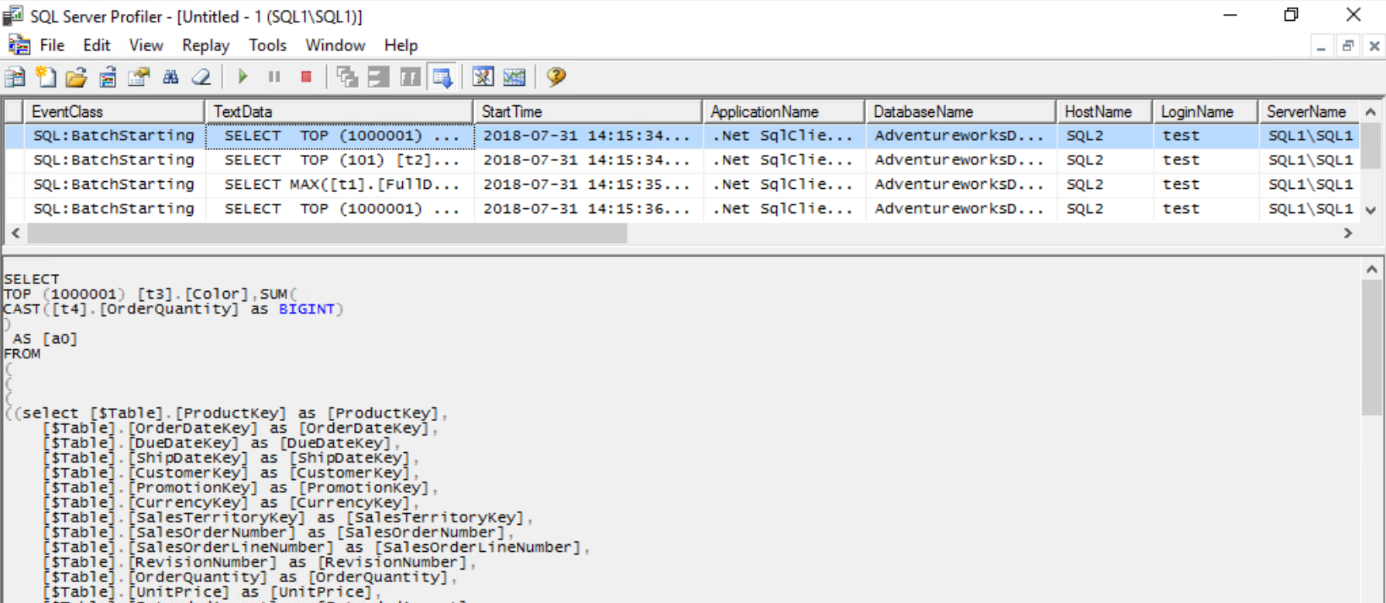
2. Arrêt de la VM SQL2

Message de Warning sur la gestion des Gateway dans le service Power BI :
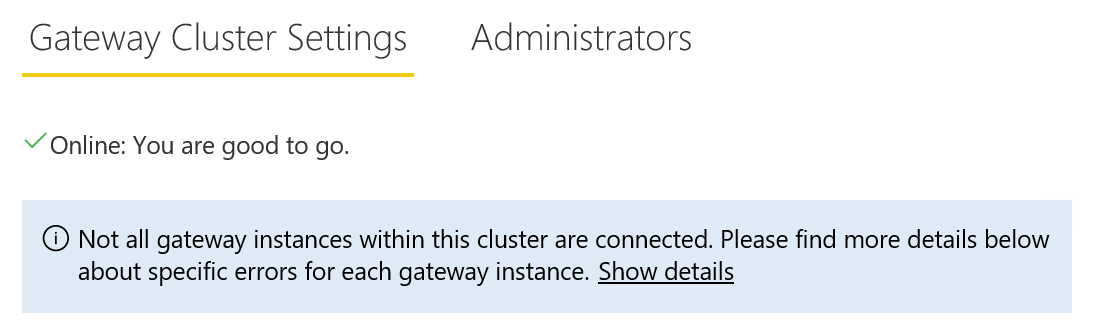
3. 2eme requête en Direct Query sur le Gateway Cluster -> HostName SQL3
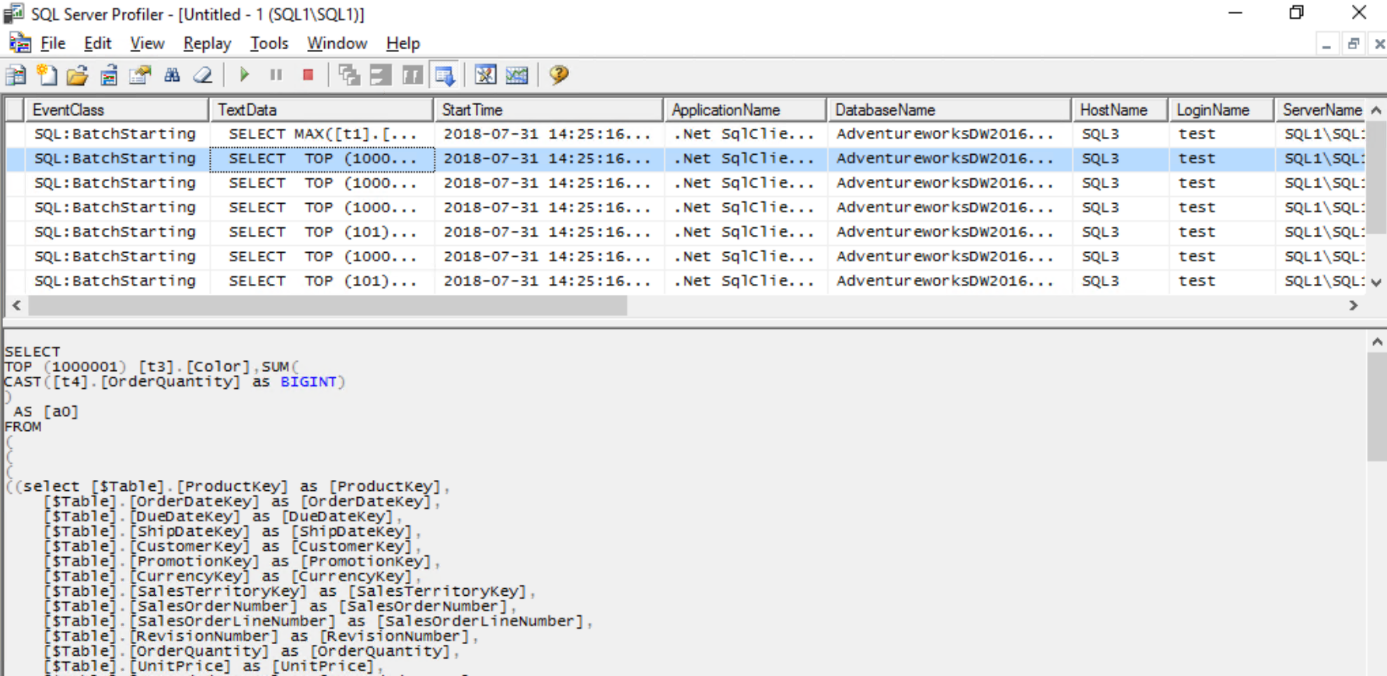
Après la perte d’un nœud du cluster, les rapports Power BI dans le service sont toujours accessibles et les requêtes en Direct Query sur la source de données On-Premise sont effectués par la passerelle active.
Il existe quelques commandes PowerShell permettant aux utilisateurs d’effectuer les opérations suivantes :
– Récupérer la liste des clusters de passerelle disponibles pour un utilisateur
– Récupérer la liste des instances de passerelle enregistrées dans un cluster, ainsi que leur statut en ligne ou hors ligne
– Modifier l’état d’activation / désactivation d’une instance de passerelle dans un cluster, ainsi que d’autres propriétés de passerelle
– Supprimer une passerelle

Load Balancing
Vous pouvez choisir de répartir le trafic entre toutes les passerelles d’un cluster. Pour cela, dans la page Gérer les passerelles du service Power BI, lorsque vous cliquez sur un cluster passerelle dans la liste de l’arborescence de navigation de gauche, vous pouvez activer l’option « Distribute requests across all active gateways in the cluster ».
Configuration :
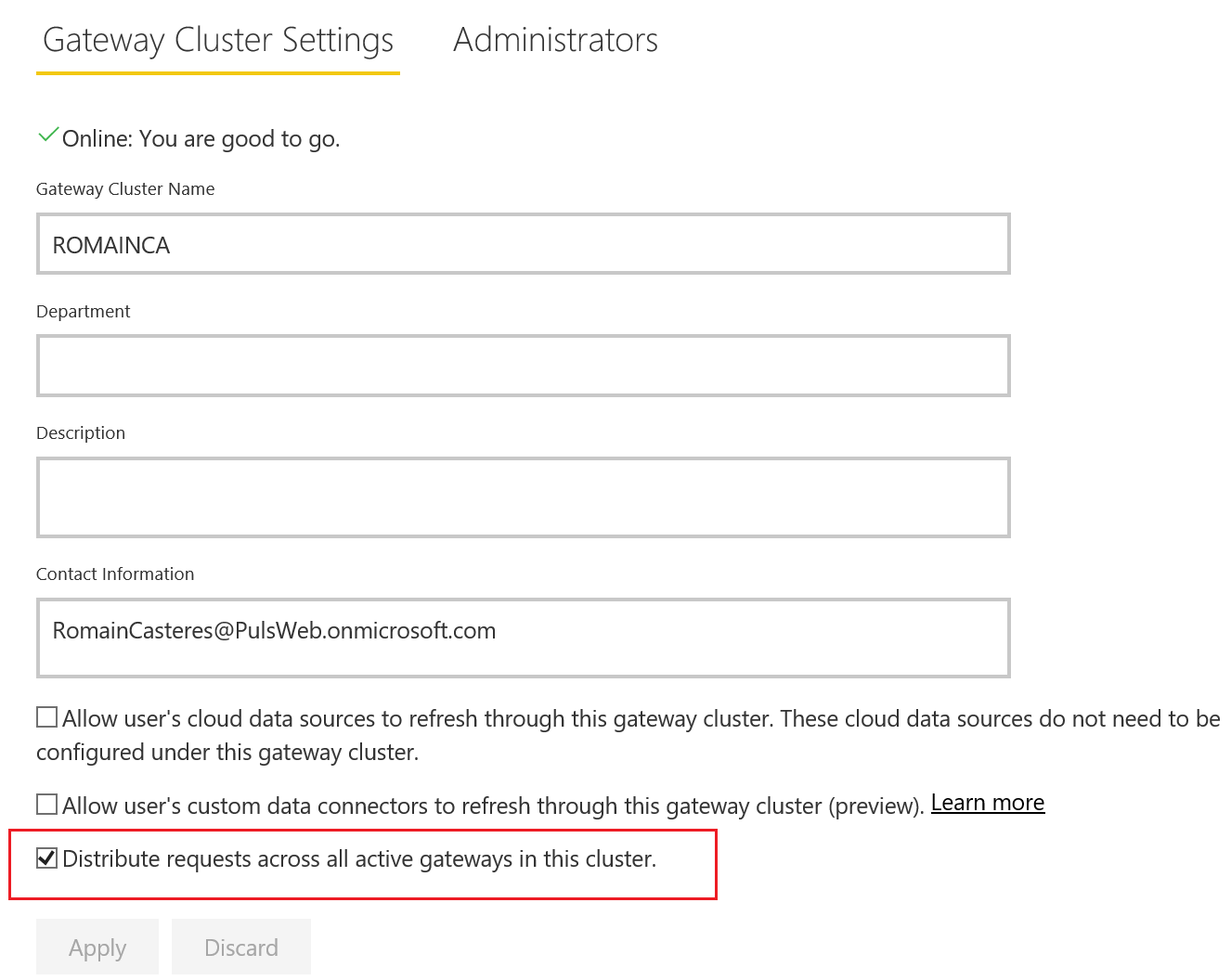
Remarque :
– Le paramètre «Allow user’s cloud data sources to refresh through this gateway cluster. These cloud data sources do not need to be configured under this gateway cluster» permet de combiner dans un même modèle des données issues de On-Premise et du Cloud. Plus d’information : https://powerbi.microsoft.com/en-us/blog/on-premises-data-gateway-february-update-is-now-available/
– Le paramètre actuellement en Preview «Allow user’s custom data connectors to refresh throught this gateway cluster» permet d’actualiser dans le service des modèles alimentés par des connecteurs personnalisés que vous auriez développés. Plus d’information : https://powerbi.microsoft.com/en-us/blog/on-premises-data-gateway-july-update-is-now-available/
Validation : Interaction avec le rapport afin de générer de nouvelles requêtes en Direct Query

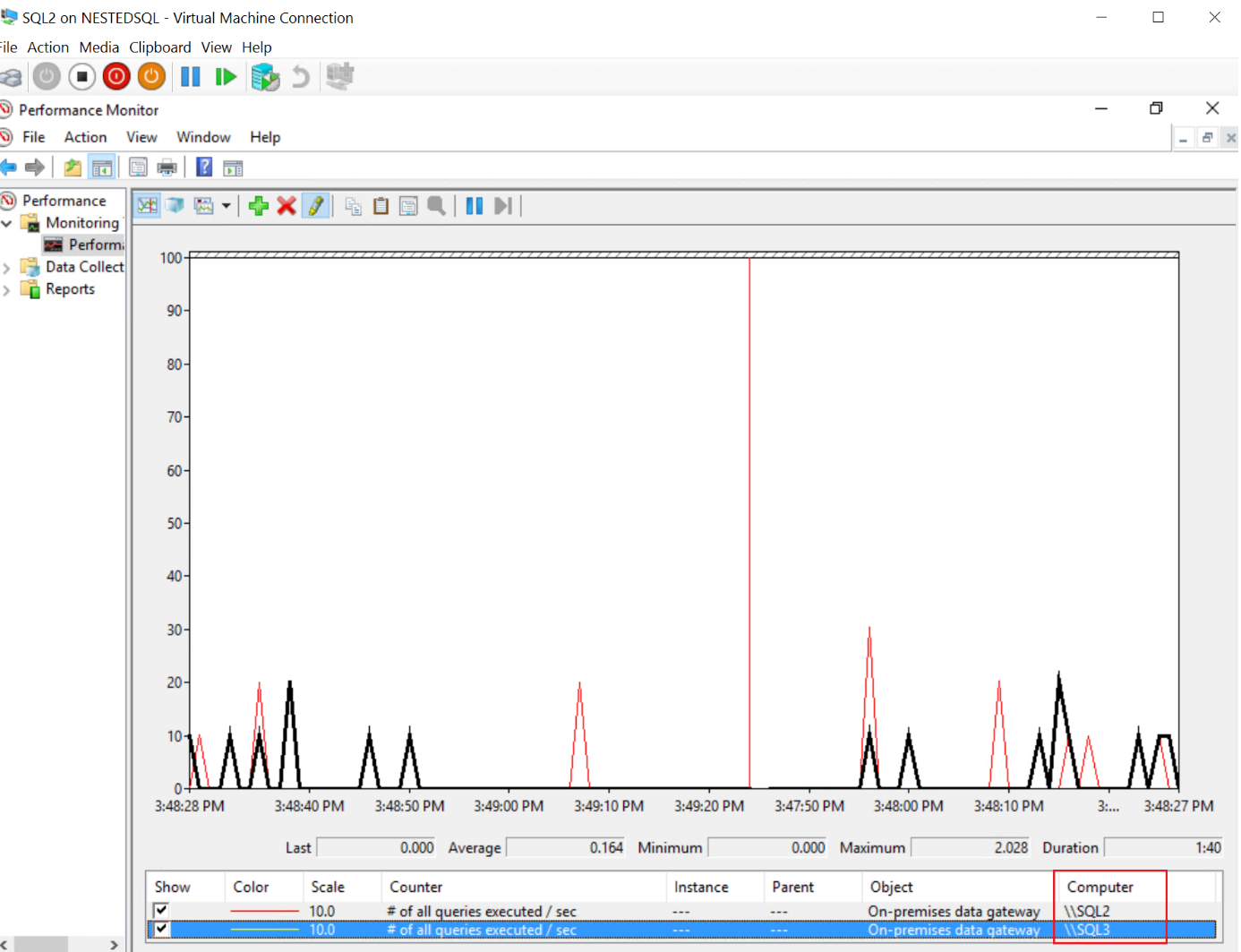
Les requêtes sont aléatoirement distribuées et traitées par les passerelles sur les serveurs SQL2 et SQL3.
Les compteurs de performance Windows fournissent des informations sur la performance d’un système, d’une application ou d’un service. Il existe des compteurs de performances liés à la passerelle :
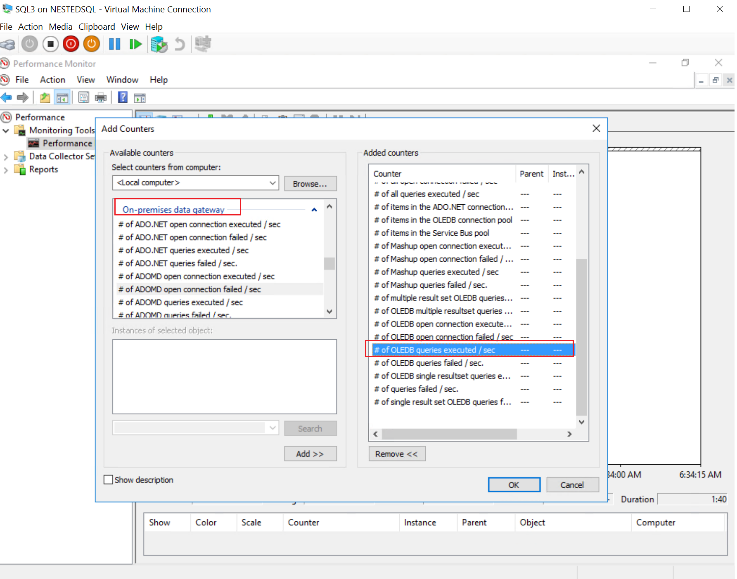
En noir les requêtes effectuées sur la passerelle installée sur le serveur SQL3 et en rouge les requêtes effectuées sur la passerelle installée sur le serveur SQL2 :
Conclusion
À travers cet article nous avons pu voir comment configurer une passerelle permettant d’analyser depuis le service Power BI des données On-Premise. Nous avons configuré un cluster permettant la haute disponibilité de ces données et enfin nous avons activé le Load Balancing pour distribuer les requêtes sur les différentes passerelles.
Ressources :
– Planning a Power BI Enterprise Deployment : https://aka.ms/pbienterprisedeploy
– Data Gateway recovery keys : Power BI Security white paper.
– Power BI Security : Article.
– Troubleshooting : https://docs.microsoft.com/en-us/power-bi/service-gateway-onprem-tshoot
– FAQ : https://docs.microsoft.com/fr-fr/power-bi/service-gateway-onprem-faq