Cet article est disponible en Anglais sur LinkedIn : Monitoring the quality of Power BI Semantics Models over time.
Introduction
Il y a plus de 3 ans, j’ai écrit un article sur l’analyse de la qualité de modèles sémantiques d’un espace de travail : Power BI Best Practice Analyzer.
Avoir des modèles de données Power BI qui ne suivent pas les bonnes pratiques sur des ressources partagées pénalise l’adoption par les utilisateurs finaux : Faible performance lors de l’actualisation ou de l’analyse, … Mais avoir des modèles de données sur les capacités qui ne suivent pas les meilleures pratiques implique également des dépenses inutiles en Unité de Capacité (CU) ! Un modèle sémantique, jusque-là crucial dans Power BI, prend une dimension encore plus importante au sein de Microsoft Fabric. Si les modèles sémantiques sont utilisés et rendus accessibles à l’ensemble de la plateforme, il est essentiel qu’ils suivent les bonnes pratiques en termes de sécurité, de performance et d’accessibilité. Leur efficacité aura un impact direct sur la consommation de CU et donc sur le coût de la plateforme, tout en affectant leur adoption par les utilisateurs finaux.
La solution présentée dans cet article peut faire partie d’un sujet de gouvernance globale au sein de l’organisation où le responsable/propriétaire de produit de données souhaite avoir une idée de la vue d’ensemble de la qualité de ses modèles de données Power BI et intégrer des normes de développement qui suivent les bonnes pratiques.
Le Best Practice Analyzer dans Tabular Editor est un outil communautaire open source développé par Daniel Otykier qui vérifie les règles standard de développement. Michael Kovalsky , de la CAT Team Fabric, a ajouté de nombreuses règles et les a rendus disponibles depuis la nouvelle librairie Python semantic-link-labs accessible depuis un Notebook Microsoft Fabric.
Maintenant, vous me voyez venir... 🚀
Comment simplifier et enrichir la première solution présentée dans mon précédent article, et analyser au fil du temps la qualité de modèles sémantique ? Examinons en détail un exemple de solution.
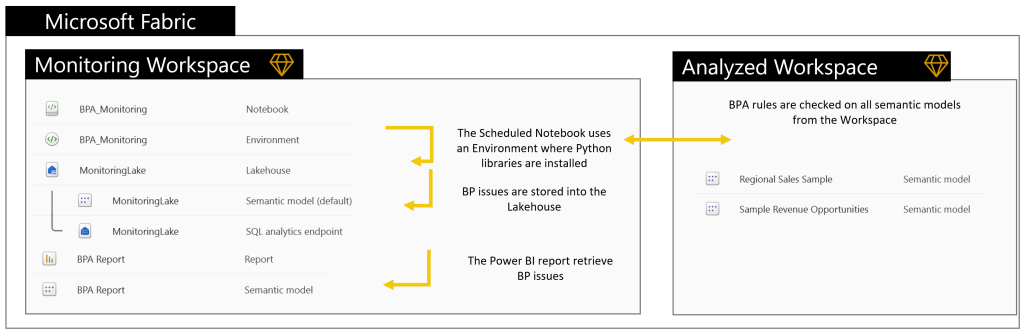
Pour l’instant, tous les objets doivent être centralisés dans un seul espace de travail, mais des mises à jour arrivent…
BPA sera exécuté à partir d’un Notebook à l’aide de la bibliothèque sempy_labs. L’utilisation d’un Notebook avec un environnement personnalisé permet de planifier des tâches en ayant préconfiguré à l’avance les bibliothèques requises et nous permet de configurer les ressources de calcul appropriées qui seront utilisées ($).
Les règles de bonnes pratiques sont disponibles à l’adresse suivante : BestPracticeRules.
💡 Vous pouvez mettre à jour ces règles même lors de l’exécution du BPA à partir d’un Notebook. L’exécution de BPA à partir de Notebook comprend plus de vérifications avec de nouvelles règles en ce qui concerne les modèles sémantiques Direct Lake.
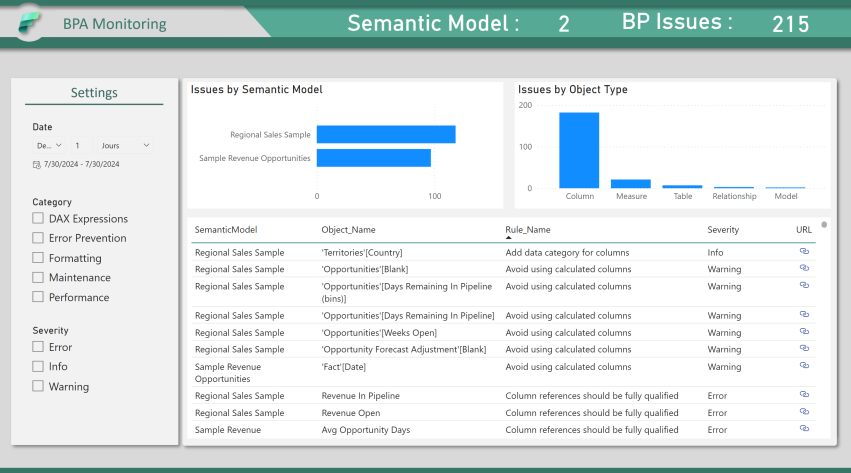
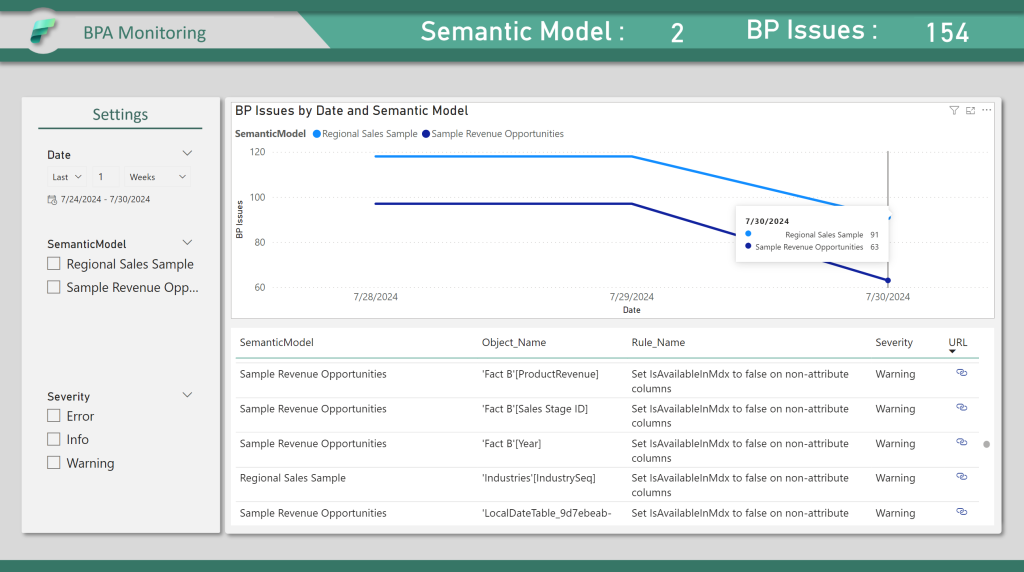
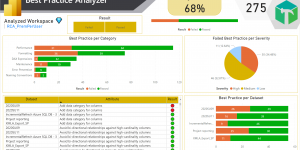
Analyse des problèmes actuels sur l’ensemble des Modèles Semantique :
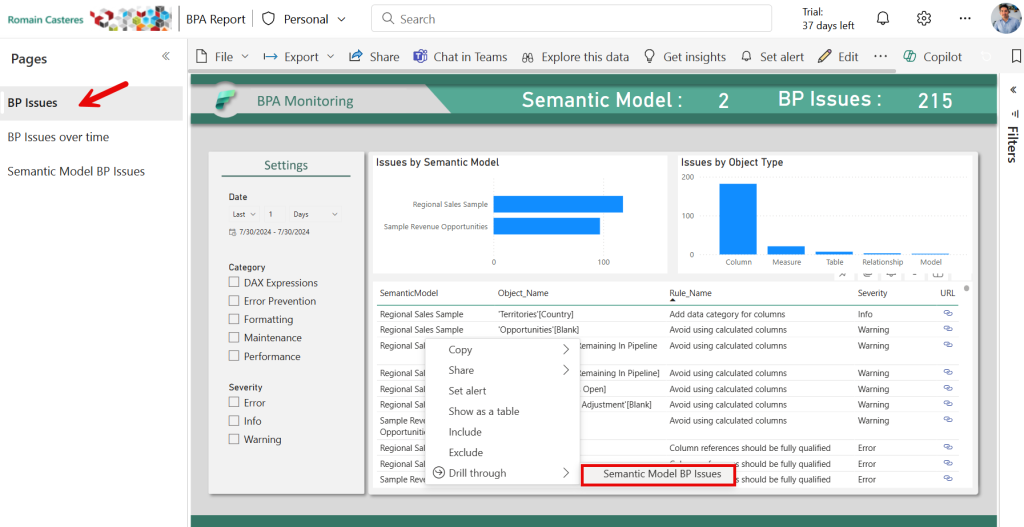
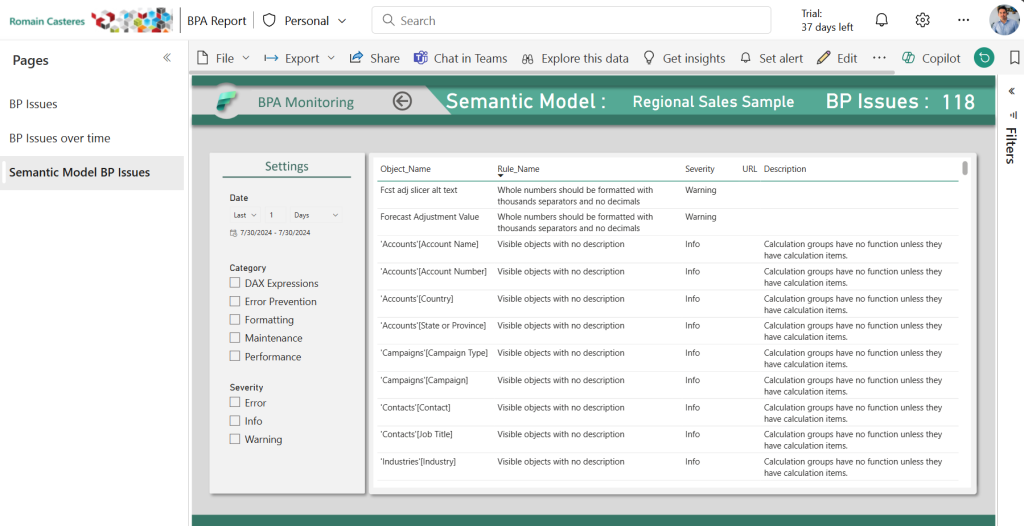
Analyse des problèmes sur un Modèle Sémantique spécifique :
Analyse des problèmes au fil du temps :
Étapes de déploiement
1 – Créez un nouveau Lakehouse
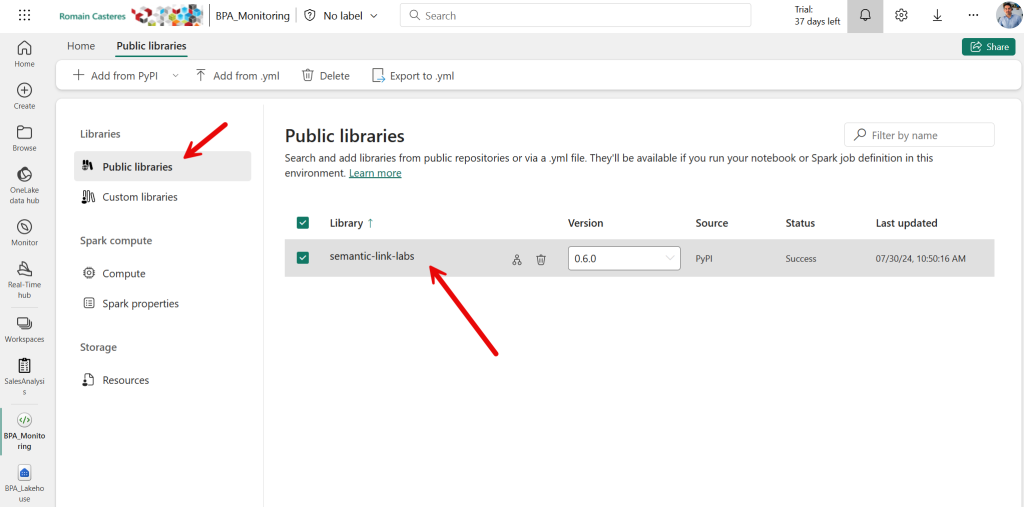
2 – Créez un nouvel environnement d’ingénierie des données et ajoutez « semantic-link-labs » en tant que bibliothèque à l’environnement. Dans « Bibliothèques publiques », cliquez sur « Ajouter à partir de PyPI » et entrez « semantic-link-labs ». Enregistrer et publier : créer, configurer et utiliser un environnement dans Fabric
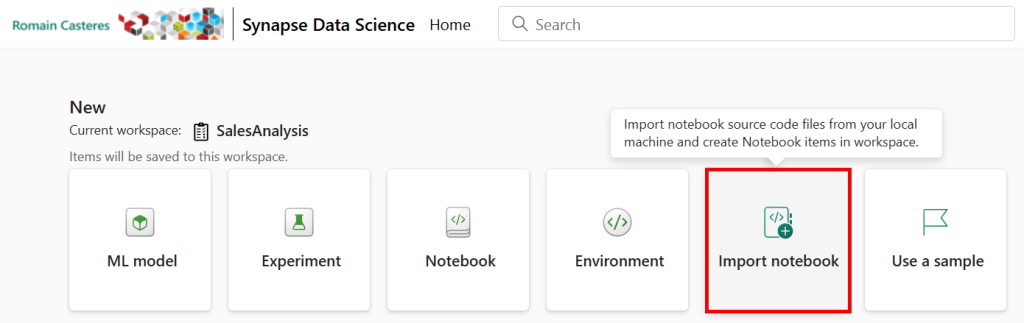
3 – À partir de l’expérience Data Science, importez le Notebook BPA_Monitoring.ipynb
4 – Associez le nouveau Lakehouse créé et le nouvel environnement au Notebook importé.
Suivez ces instructions pour connecter les Lakehouses
Suivez ces instructions pour créer, configurer et utiliser un environnement dans Fabric
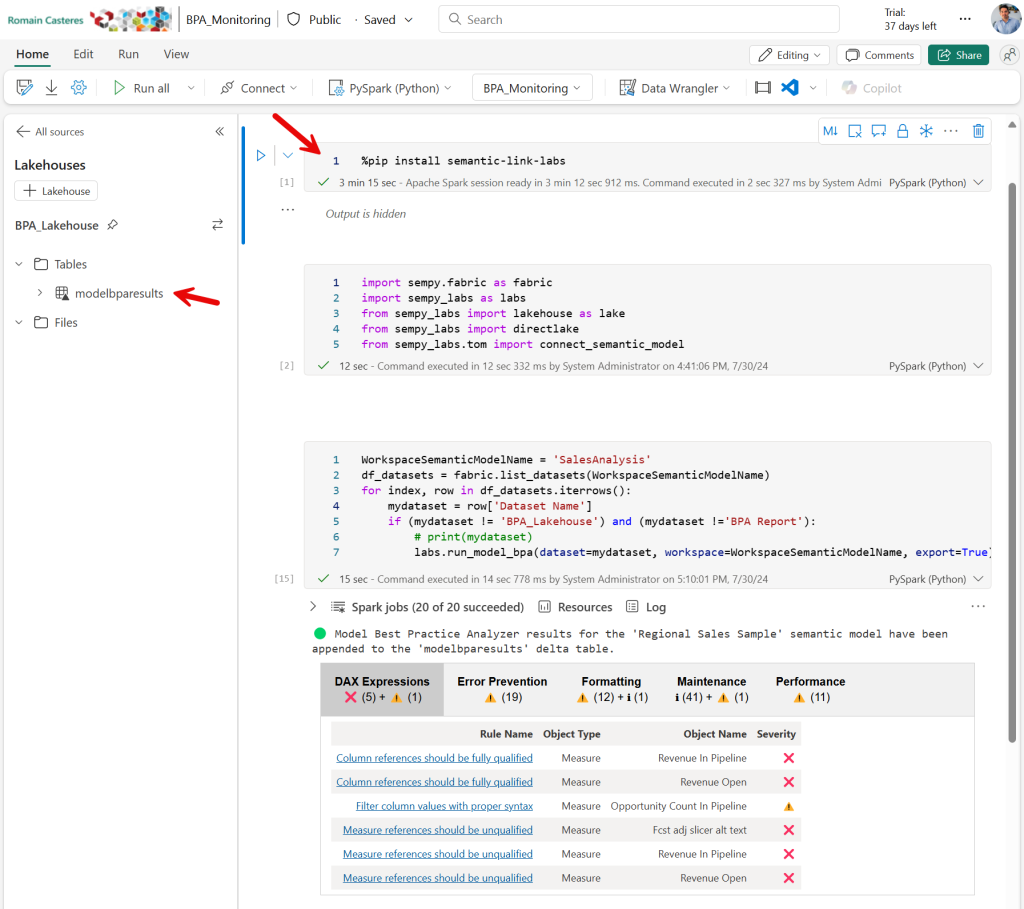
5 – Vous pouvez exécuter le Notebook manuellement en décommentant la première cellule pour installer la bibliothèque requise et vérifier que les problèmes de qualités sont enregistrés avec la table « modelbparesults » du Lakehouse :
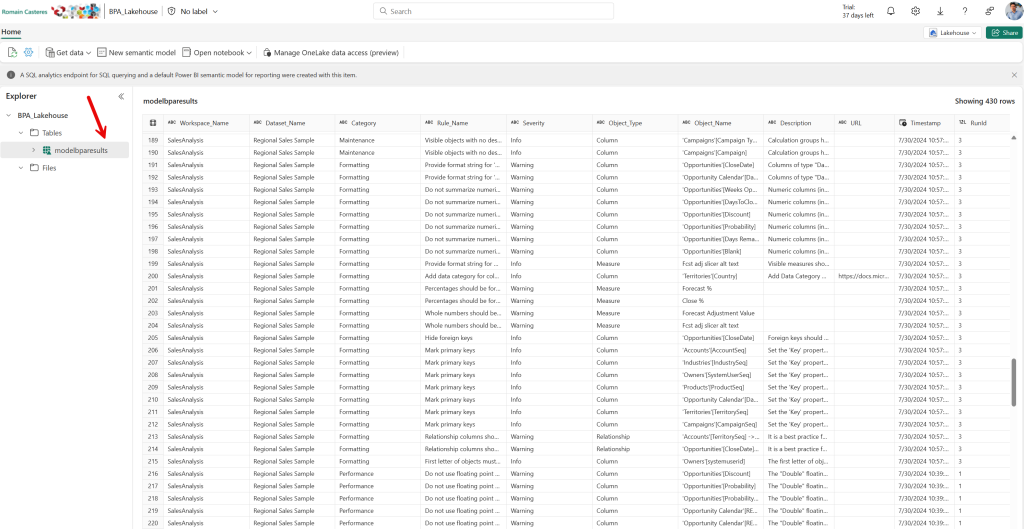
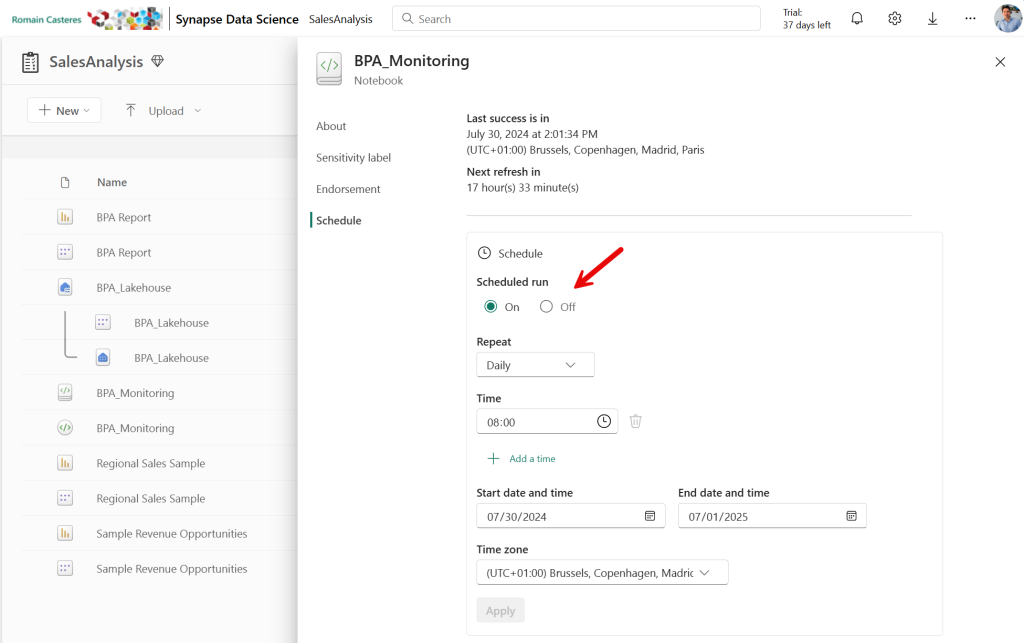
6 – Programmez l’exécution du Notebook :
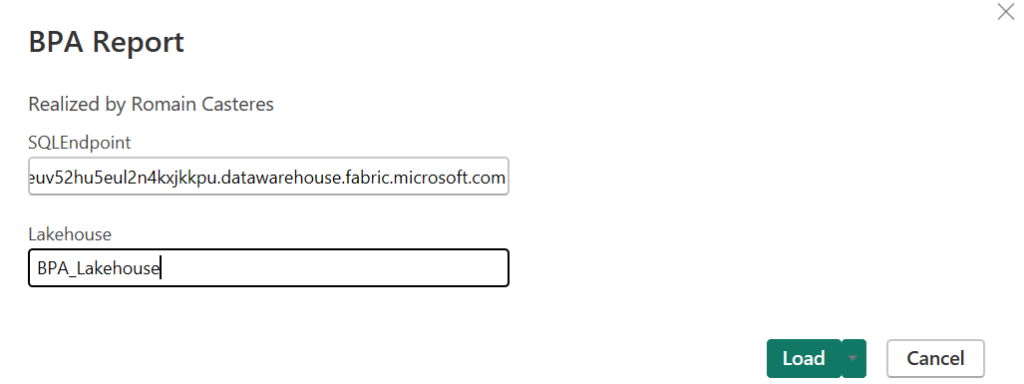
7 – Ouvrez le Template Power BI BPA Report.pbit et entrez la chaîne de connexion du point de terminaison SQL du Lakehouse ainsi que le nom de la base de données :
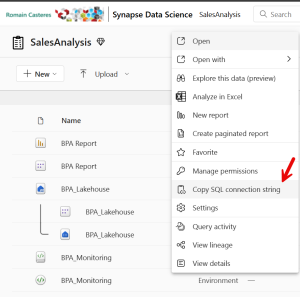
Ouverture du modèle Power BI :
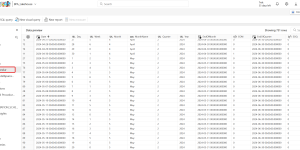
La requête Power Query retourne uniquement la dernière exécution pour chacun des modèles sémantiques par jours.
8 – Programmez l’actualisation du modèle sémantique ou ajoutez une étape supplémentaire au Notebook avec une commande refresh_semantic_model :

Conclusion
Nous avons vu comment surveiller la qualité des modèles sémantiques au fil du temps sans quitter Microsoft Fabric.
Maintenant, j’ai beaucoup d’idées sur la façon d’enrichir cette première solution :
- Mettre à jour le semantic-link-labs pour permettre l’exportation des problèmes de qualité dans un Lakehouse en dehors de l’espace de travail et permettre l’analyse de plusieurs espaces de travail
- Interrogez le modèle sémantique de la Metrics App pour recueillir la consommation CU des modèles sémantiques et corréler ces informations avec leur qualité
- Interroger les informations et les journaux d’activité des requêtes DAX depuis Azure Log Analytic
- Étant donné que le modèle créé est en mode d’importation, vous pouvez ajouter du RLS et partager le rapport au sein de votre organisation pour suggérer des améliorations (sans avoir besoin de charger toutes les données sur le OneLake)
- Créer une alerte pour les propriétaires de modèles sémantiques en cas d’avertissement de gravité élevée
- Changer le mode d’accès du modèle sémantique en Direct Lake
- Enrichissez le Lakehouse et créez des rapports avec Vertipaq Analyzer
- …
📢 N’hésitez pas à ajouter des commentaires et à voter sur certaines de ces idées, je vais essayer d’enrichir la première solution en fonction de vos retours.

Pingback: Génération d'une dimension Date pour les modèles sémantiques en Direct Lake - Pulsweb - Romain Casteres