1 – Introduction
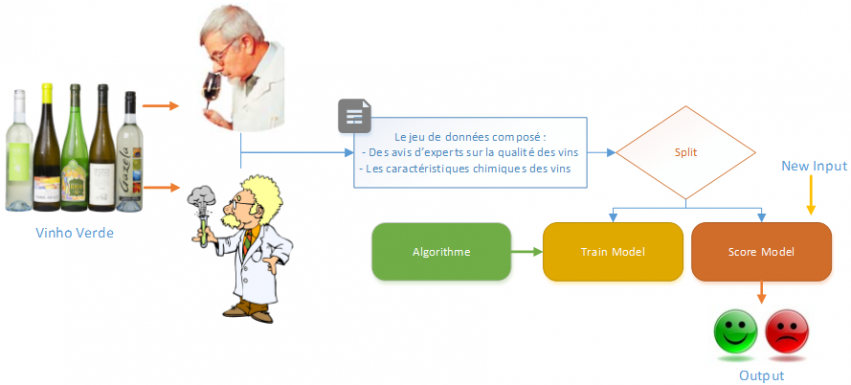
Dans cet article je vais présenter le service Cloud Azure ML de Microsoft. C’est à travers un exemple concret, une problématique bien réelle que nous aborderons l’outil : Comment prédire la qualité d’un vin en fonction de ses caractéristiques !
Avant de rentrer dans le vif du sujet nous verrons dans un premier temps ce qu’est le Machine Learning, quel est son but et quels sont les différents algorithmes utilisés pour l’apprentissage automatique. Dans un second temps je ferai un focus sur l’outil Azure ML proposé par Microsoft et sur ses caractéristiques. Par la suite je présenterai le jeu de données utilisé pour notre analyse, nous testerons et évaluerons différents algorithmes de prédiction dans le but d’obtenir le « meilleur » modèle. Enfin nous publierons notre expérimentation à travers un Web Service que nous interrogerons via un ETL (SSIS) pour simuler une industrialisation, une mise en production de notre algorithme.
Remarque :
- Cet article n’a pas vocation à être un cours sur le Machine Learning.
- J’ai cherché un jeu de données pour avoir un support de rédaction. C’est après une étude de marché que j’ai écrit cet article, je me suis dit, qu’au moins en France, je toucherai un large public ! (Dédicace à une chanson du groupe Java « Sexe, Accordéon Et Alcool »)
- Ayant peu de connaissances en œnologie, je ne garantis pas la véracité de mes résultats, mais n’hésitez pas à les commenter 😉
2 – Machine Learning
L’apprentissage automatique ou le Machine Learning est une discipline scientifique où l’analyse et l’implémentation de méthodes automatisables permet à une machine d’évoluer grâce à un processus d’apprentissage.
“The goal of machine learning is to build computer systems that can adapt and learn from their experience.” – Tom Dietterich

Dilbert (Jan 5, 2000)
L’utilisation de l’apprentissage automatique reste encore principalement utilisé dans le secteur de l’informatique et de la statistique. Avec la multiplication des données, de leurs nouveaux types, de leurs fréquences, …, du Big Data, ces algorithmes commencent à être utilisés dans plusieurs domaines et dans plus en plus de sociétés. Avec cette démocratisation, il devient impératif pour ceux qui utilisent ces algorithmes de comprendre leur signification et leur potentiel impact.
Le principe du Machine Learning est de créer un modèle à partir d’un jeu de données, duquel on peut évaluer les performances par une méthode de validation sur un sous-ensemble de ce jeu de données. Plus la taille du jeu de données utilisé sera grande et plus le modèle entraîné sera performant. C’est surement pour cela que l’on amalgame souvent le Machine Learning au Big Data.
La démocratisation du Big Data aurait-elle pour incidence la démocratisation du Machine Learning ?
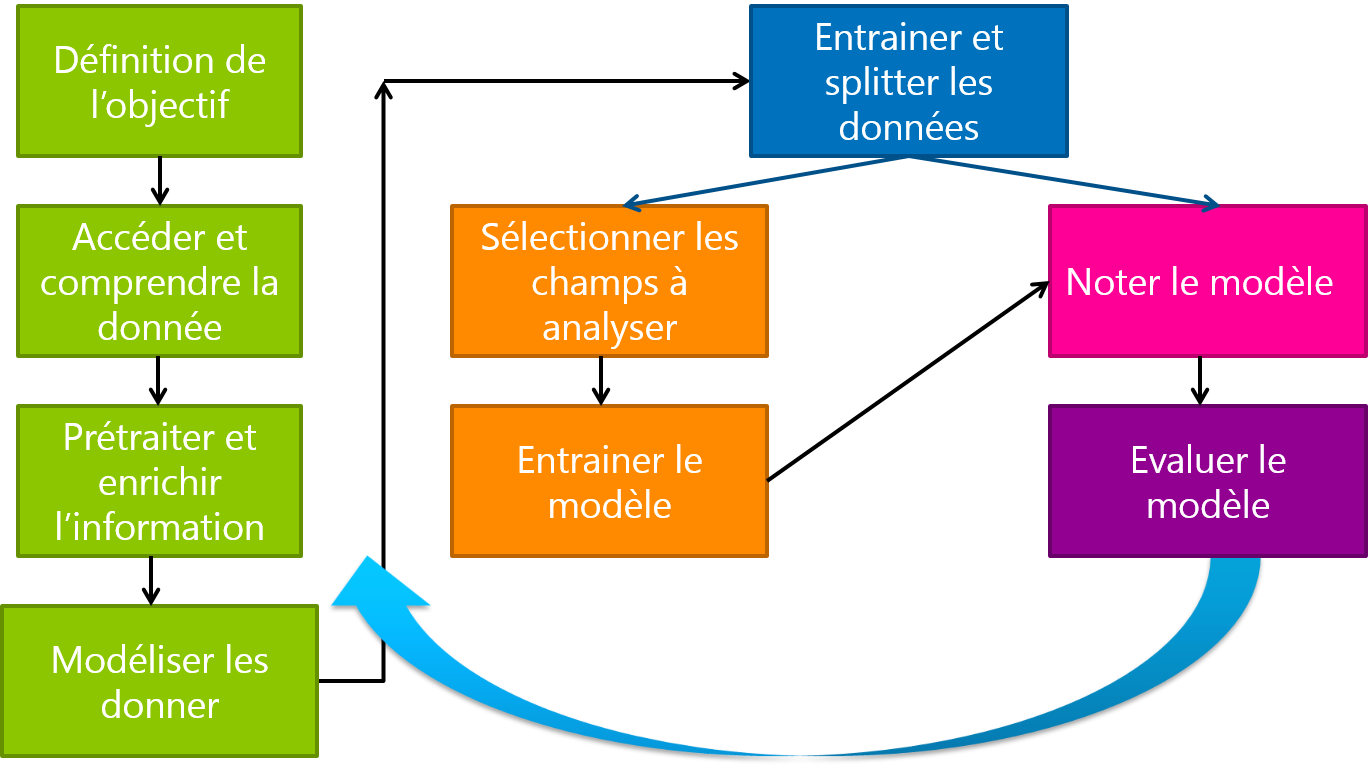
Voici les principales étapes quant à la construction d’un modèle prédictif :
Les algorithmes d’apprentissage sont nombreux et peuvent se catégoriser selon le mode d’apprentissage qu’ils emploient :
- Apprentissage supervisé
- Apprentissage non supervisé
- Apprentissage semi-supervisé
- Apprentissage par renforcement
Dans le domaine de l’apprentissage supervisé, voici quelques algorithmes :
-
Linear Classifier : Il permet de classifier selon une combinaison linéaire des caractéristiques.
-
o Logical Regression : La régression logistique est une technique statistique connue utilisée pour modéliser les résultats binaires. Utilisation : Exploration et évaluation des facteurs qui contribuent à un résultat comme par exemple rechercher les facteurs qui influencent les clients à se rendre plusieurs fois dans un magasin.
-
o Naïve Bayes Classifier : Permet de classifier facilement et rapidement. Utilisation : Catégoriser les bons et mauvais clients.
-
o Perceptron : C’est un algorithme de techniques de séparation linéaire (Université de Lille 3)
-
o Support Vector Machine : C’est un algorithme d’apprentissage supervisé destiné à résoudre des problèmes de discrimination et de régression reposant sur deux idées clés, la marge maximale et le fait de transformer l’espace de représentation des données d’entrée en un espace de plus grandes dimensions. Utilisation : Les SVM peuvent être utilisés pour résoudre des problèmes de discrimination, c’est-à-dire décider à quelle classe appartient un échantillon, ou de régression, c’est-à-dire prédire la valeur numérique d’une variable.
-
Quadratic Classifiers : Un classificateur quadratique est utilisé pour séparer les données en deux ou plusieurs classes d’objets à l’aide d’une surface quadratique.
-
K-Means Clustering : L’algorithme des k-moyennes divise des observations en K partitions (clusters) dans lesquelles chaque observation appartient à la partition avec la moyenne la plus proche. Utilisation : K-Means est utile lorsque vous avez une idée du nombre de partitions existantes dans votre espace.
-
Boosting : Le Boosting optimise les performances d’algorithmes de classification binaires. C’est une méthode pour convertir des règles de prédiction peu performantes en une règle de prédiction (très) performante. La prédiction finale est issue d’une combinaison (vote pondéré) de plusieurs prédictions.
Utilisation : Prédiction de courses hippiques. -
Decision Tree : C’est un algorithme de classification et de régression utilisé pour la modélisation prédictive d’attributs discrets et continus. L’algorithme est facile à appréhender. Utilisation : identifier les caractéristiques d’un client.
-
o Random Forest : L’algorithme des forêts d’arbres décisionnels effectue un apprentissage sur de multiples arbres de décision entrainés sur des sous-ensembles de données légèrement différents.
-
Neural Networks : L’algorithme associe chaque état possible de l’attribut d’entrée avec chaque état possible de l’attribut prévisible, et il utilise les données d’apprentissage pour calculer les probabilités. Utilisation : Prédiction des stocks.
-
Bayesian Networks : L’algorithme calcul des probabilités conditionnel. En fonction des informations observées, il calcule la probabilité des données non observées. Par exemple, en fonction des symptômes d’un malade, on calcule les probabilités des différentes pathologies compatibles avec ses symptômes. On peut aussi calculer la probabilité de symptômes non observés, et en déduire les examens complémentaires les plus intéressants. Utilisation : Modélisation des risques.
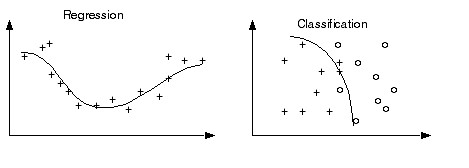
Il existe deux types de modèle en fonction de la nature de la sortie attendue :
-
Classification : La variable cible est catégorique et sa « classe » est identifiée.
-
Régression : La variable cible est continue.
Après avoir recueilli des données, les avoir nettoyées, enrichies, avoir sélectionné leurs caractéristiques, choisi le modèle en fonction de la sortie attendue et du type de vos données, entrainé le modèle, il est désormais temps de l’évaluer à l’aide des méthodes suivantes :
-
Model Scoring : Processus qui applique les paramètres du modèle à un ensemble de données pour générer des prévisions.
-
Model Evaluation : Calcule la performance du modèle en fonction du Model Scoring et mesure la capacité d’un modèle à apprendre la relation entre les caractéristiques et les objectifs.
Tout cela reste encore très théorique… Passons à la pratique !
3 – Azure ML
Azure Machine Learning est un service permettant de réaliser des analyses prédictives. En tirant parti du Cloud, Azure ML permet à un large public d’accéder à l’apprentissage automatique depuis un navigateur internet. En effet l’apprentissage automatique requiert généralement des logiciels complexes, des ordinateurs haut de gamme et des Data Scientist. Pour de nombreuses start-ups et même pour de grandes entreprises, cette technologie reste trop compliquée et trop chère.
Azure ML combine des outils d’analyse, des algorithmes puissants développés pour Xbox et Bing et des années de recherches menées par Microsoft en matière d’apprentissage automatique en un service Cloud simple et convivial.
Voici un historique des actions de Microsoft sur le Machine Learning :
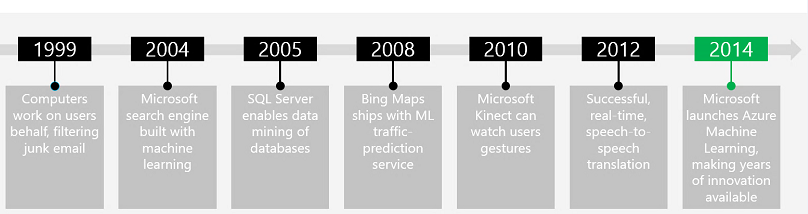
Vidéo de présentation sur Channel 9.
Azure ML est disponible en Preview depuis le Juillet 2014, pour l’essayer : http://azure.microsoft.com/fr-fr/services/machine-learning/.
Après avoir créé un Workspace, espace de travail, il est possible d’uploader des données, créer des expérimentations, publier des Web Services… Voici à quoi ressemble la fenêtre de création d’expérimentation:
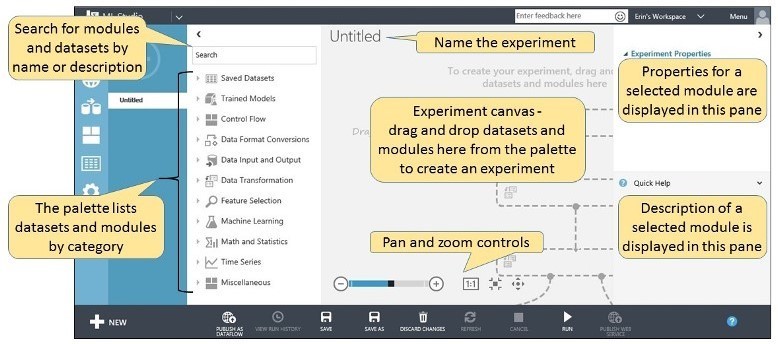
Un certain nombre de modules permettent de formater, corréler, transformer les données… Ils sont organisés par types d’action :
• Data Format Conversions
• Data Input and Output
• Data Transformation
• Feature Selection
• Machine Learning
• R Language Modules
• Statistical Functions
• Text Analytics
Voici la liste exhaustive des modules : Studio AzureML
Les données d’entrée peuvent aujourd’hui être récupérées des sources suivantes :
• Azure Blob Storage
• HTTP
• Azure Table
• SQL Azure
• Hive Query
• Power Query
Il est possible d’enregistrer les résultats d’une expérimentation dans les destinations suivantes :
• Azure Blob Storage
• Azure Table
• SQL Azure
• Hive Query
Le service Azure ML est facturé par heure lors de l’expérimentation. Le service d’API est lui facturé aux 1000 appels. Pour plus de détails : https://azure.microsoft.com/fr-fr/pricing/details/machine-learning/.
4 – Les données
Parlons maintenant du jeu de données sélectionné : il a été recueilli par Paulo Cortez, Antonio Cerdeira, Fernando Almeida, Telmo Matos et Jose Reis en 2009 pour la rédaction du livre : Modeling wine preferences by data mining from physicochemical properties.
Citation for use: P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
Ils proposent une approche d’exploration de données pour prédire les préférences gustatives et la qualité de différents vins en fonction de leurs caractéristiques : fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates, alcohol.
Les échantillons proviennent de vins blancs et rouges du Portugal : Vinho Verde. Vinho Verde est un produit de la région de Minho, au Nord-Ouest du Portugal. Moyennement alcoolisé, il est particulièrement apprécié en raison de sa fraicheur 😉
Les données sont publiques, vous pourriez donc reproduire mes expérimentations : http://www3.dsi.uminho.pt/pcortez/wine/winequality.zip.
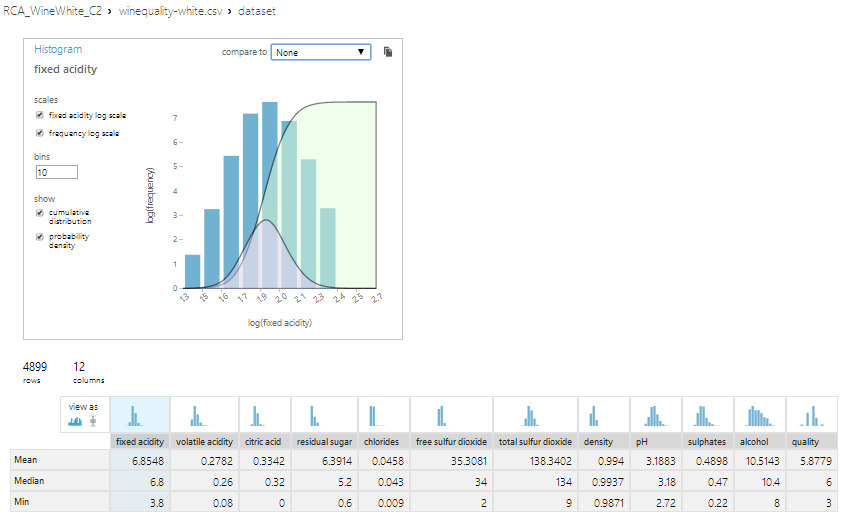
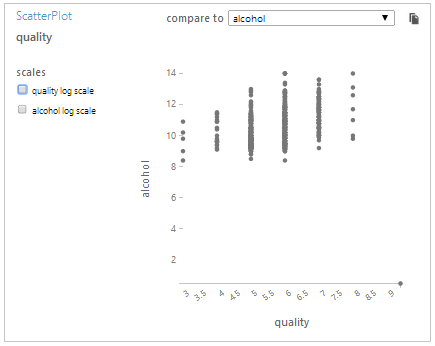
Voici à quoi ressemblent les données :
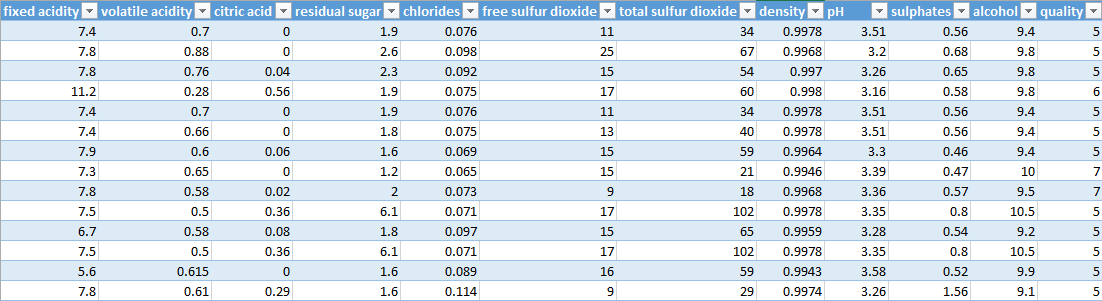
L’output variable dans notre exemple sera la qualité. Cette donnée est basée sur des données sensorielles médianes d’au moins 3 évaluations faites par des experts en vin. Chaque expert a classé la qualité du vin entre 0 (très mauvais) et 10 (excellent).
Le nombre de vins testés est de 1599 pour les rouges et de 4898 pour les blancs.
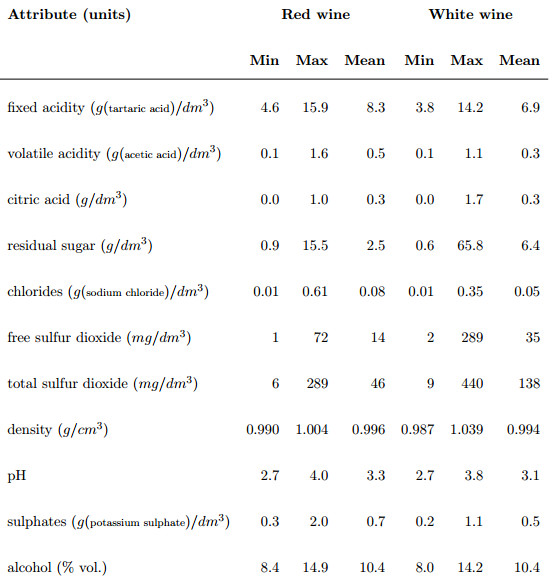
Voici les Inputs variables, leurs unités, leurs Min, Max et leurs moyennes (Il ne manque aucun attribut à un vin) :
5 – Classification
5.1 – Classification Binaire
Avant de commencer mon expérimentation, revenons sur ce que nous souhaitons faire et obtenir :
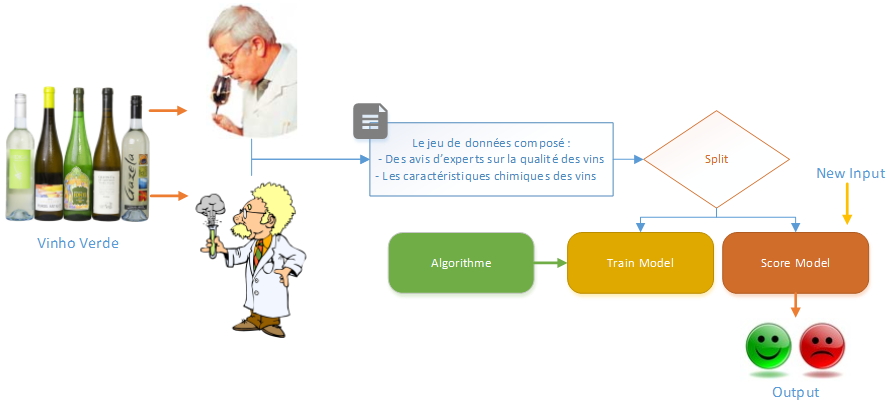
Voici les différentes étapes :
- Upload du jeu de données
- Division du jeu de données : une partie pour entrainer le modèle et l’autre permettant de vérifier les résultats du modèle
- Vérification des résultats de l’algorithme choisi, sinon itération
- Définition des points d’entrées et de sorties du modèle (New Input, Output)
- Publication du Web Service
- Utilisation de l’API
- Validation des résultats par une dégustation ;-p
Il existe plusieurs types de classification selon le résultat souhaité, afin d’avoir un résultat binaire sur la qualité du vin j’ai initié le fichier CSV suivant : Vous pouvez le télécharger ici.
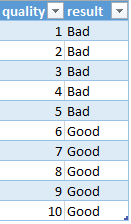
Nous allons le corréler avec le fichier des vins rouges afin de prédire si un vin rouge est bon ou mauvais en fonction de sa composition chimique. Premièrement nous devons créer depuis le Manager Azure, le service Machine Learning :
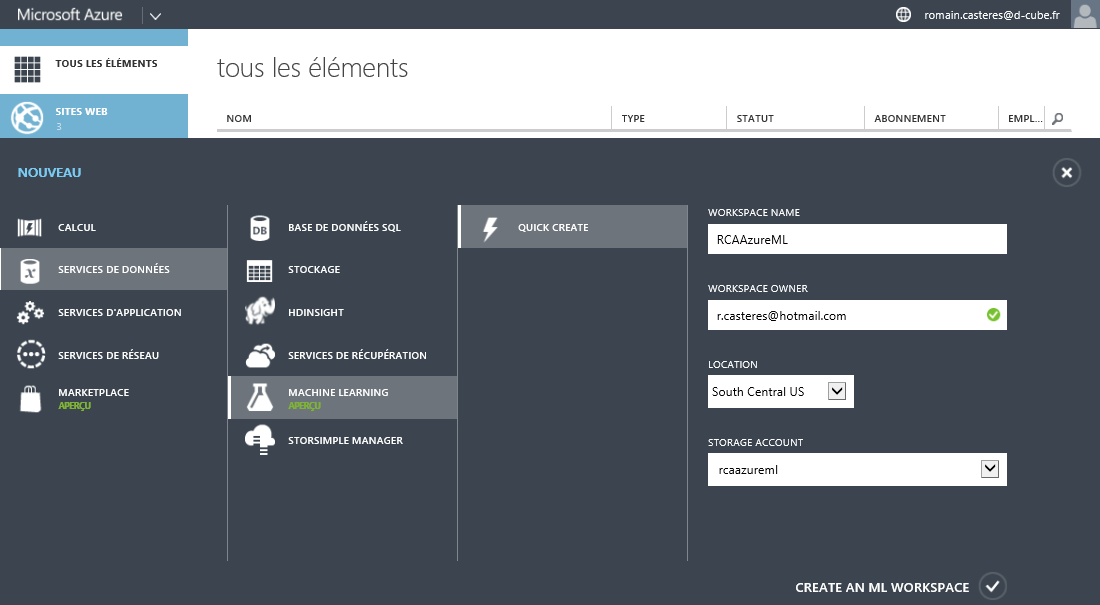
Remarque : Seul le stockage South Central US est disponible pour le moment.
Une fois le Workspace créé, je m’y connecte :
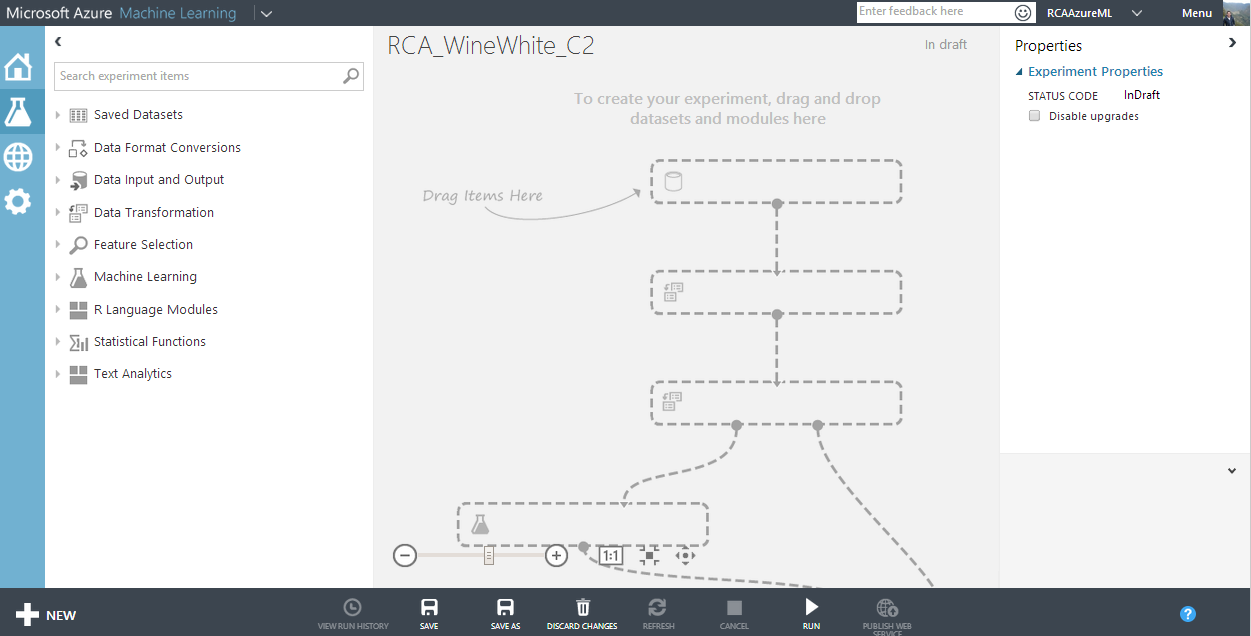
Upload des différents fichiers et création d’une nouvelle expérimentation :
Il est possible de visualiser et d’analyser les données d’un fichier d’entrée :
Voici une première expérimentation :
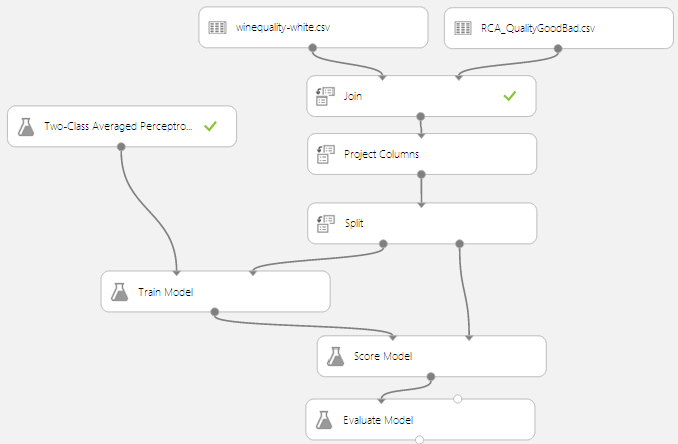
Détail des étapes :
- Join : Jointure entre les deux tables sur la colonne Quality.
- Project Columns : sélection de toutes les colonnes hormis les colonnes Quality (nous n’en avons plus besoin car nous souhaitons prédire la colonne Result).
- Split : Split des données en deux échantillons, l’un pour entrainer le modèle et l’autre pour le valider.
- Train model : J’ai choisi d’entrainer le modèle avec l’algorithme Two-Class Averaged Perceptron (ne me demandez pas pourquoi !), sur la colonne Result.
- Score Model : Permet de calculer le score du modèle.
- Evaluate Model : Permet d’évaluer le modèle.
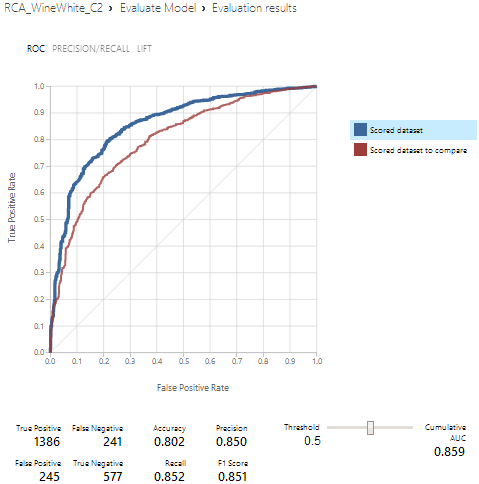
Après exécution de mon expérimentation, voici le résultat :
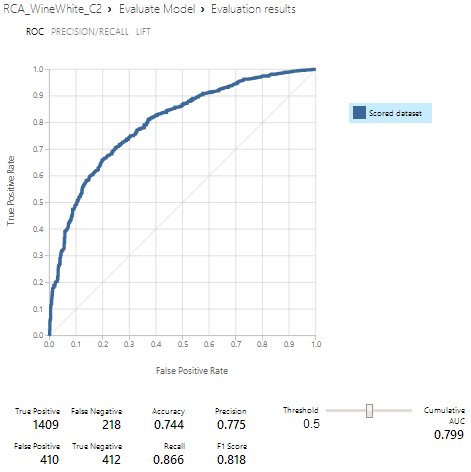
La qualité d’un modèle est mesurée par l’évaluation de la performance du modèle sur une partie des données sources pour mesurer la précision des prédictions en les comparant aux résultats connus attendus.
Receiver Operating Characteristics (ROC) est une technique permettant de visualiser, organiser et sélectionner des classificateurs sur la base de leur performance.
Pour les modèles de classification binaires, il y a quatre résultats possibles :
• Vrai positif (TP) : un vin bon est correctement classé comme bon
• Faux positif (FP) : un vin mauvais qui est incorrectement classé comme bon
• Vrai négatif (TN) : un exemple mauvais qui est correctement classé comme mauvais
• Faux négatif (FN) : un exemple bon qui est incorrectement classé comme mauvais
Il existe trois paramètres importants qui sont utilisés pour mesurer la performance :
• Precision : elle est calculée par TP / (TP + FP)
• Recall : Calculé par TP / (TP + FN)
• Accuracy : elle est calculée par TP + TN / (TP + FP + TN + FN)
Au vue des résultats mon classificateur est moyennement bon. Sur 1819 bons vins il s’est trompé 410 fois, et sur les 630 mauvais vins il s’est trompé 218 fois !
Comparons les résultats avec d’autres classificateurs et itérons afin d’avoir le meilleur taux de prédiction :
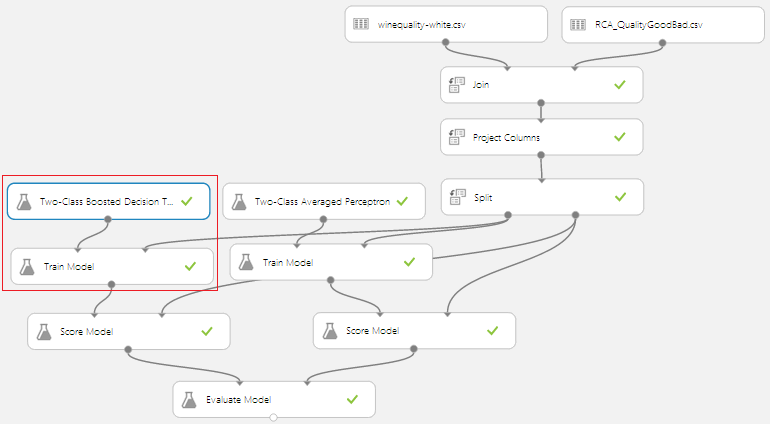
Le classificateur « Two-Class Boosted Decision Tree » offre de meilleures prédictions :
Après avoir testé et gardé le meilleur classificateur (il s’avère que dans mon cas c’est le « Two-Class Decision Jungle ») il faut sauvegarder le modèle entrainé pour pouvoir le réutiliser :
Remarque : la plupart des algorithmes possèdent des paramètres modifiables comme le nombre de Learning itérations, de Learning rate, … influant sur les performances.
Réutilisation du modèle entrainé :
Il nous reste à définir un point d’entrée et de sortie au modèle :
Publier le Web Service :
Test du Web Service :
Il est possible de tester dès à présent l’API en rentrant les différentes caractéristiques d’un vin afin de prédire s’il est bon ou mauvais !
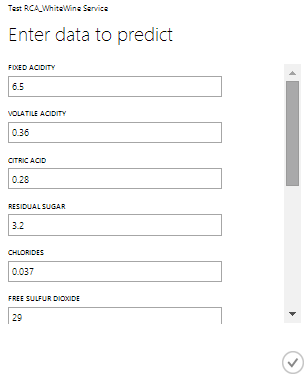
Voici les caractéristiques d’un vin :
• FIXED ACIDITY : 6.5
• VOLATILE ACIDITY : 0.36
• CITRIC ACID : 0.28
• RESIDUAL SUGAR : 3.2
• CHLORIDES : 0.037
• FREE SULFUR DIOXIDE : 29
• TOTAL SULFUR DIOXIDE : 119
• DENSITY : 0.9908
• PH : 3.25
• SULPHATES : 0.65
• ALCOHOL : 13
Résultat :

Le vin devrait être bon à 97 % !
5.2 – Classification Multi-Class
Dans l’exemple précédent nous avons classifié la qualité d’un vin avec les attributs « Bon » et « Mauvais », dans cet exemple nous analyserons la qualité d’un vin avec des chiffres entre 0 et 10. Pour ce faire nous devons utiliser d’autres algorithmes de classification Multi-Class mais le principe reste le même.
Voici l’expérimentation :
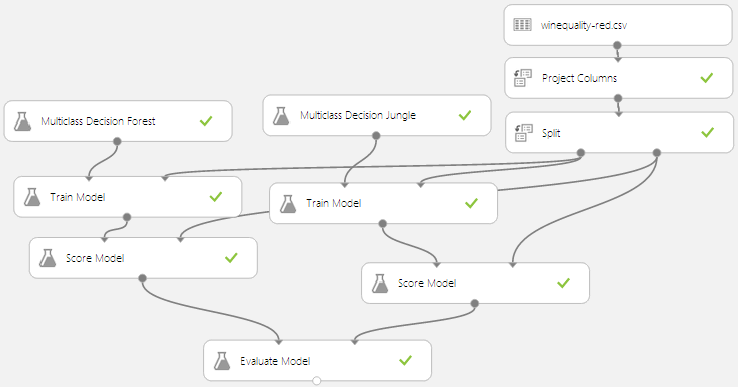
Voici les résultats après quelques ajustements sur les propriétés des classifieurs :
En apprentissage supervisé, le concept d’ajustement consiste à chercher une fonction de prédiction qui, au moyen d’attributs prédictifs, permet d’ajuster au mieux l’attribut à prédire. Ceci conduit à s’intéresser à la distribution de la variable d’output pour les différentes combinaisons de valeurs des attributs, c’est-à-dire à la représentation sous forme de table de contingence des données.
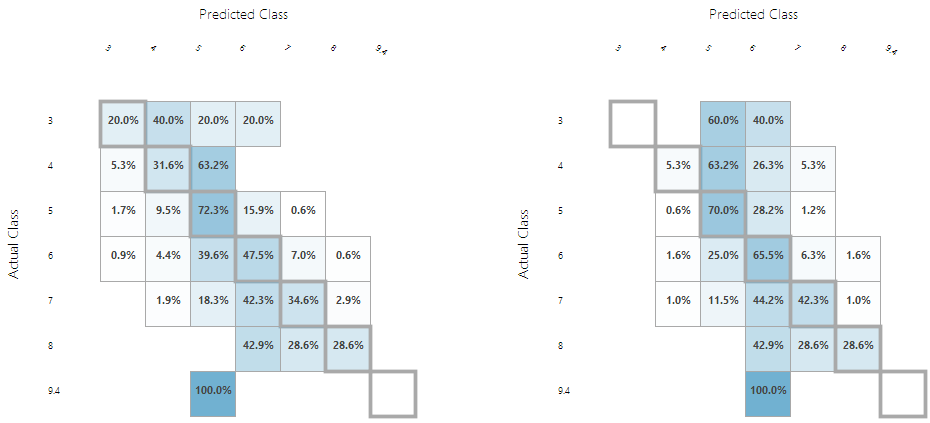
Les résultats de gauche correspondent au classifieur « Multiclass Decision Forest » celui de droite au classifieur « Multiclass Decision Jungle ».
Voici comment lire ces résultats :
• Rappelons que le modèle entrainé (avec une partie des données sources) est évalué à l’aide des données source, une comparaison entre les prédictions et les données réelles est donc effectuée pour mesurer l’efficacité du modèle à prédire de nouveaux jeux de données.
• Le classifieur « Multiclass Decision Forest » fournit au global de meilleures prédictions, en effet plus les données situées sur la transversale sont hautes moins le modèle se trompe.
• Le classifieur « Multiclass Decision Forest » a trouvé pour des vins de qualités 3 :
o 20 % des vins analysés en qualité 3 : bonne prédiction
o 40 % des vins analysés en qualité 4 : mauvaise prédiction
o 20 % des vins analysés en qualité 5 : mauvaise prédiction
o 20 % des vins analysés en qualité 6 : mauvaise prédiction
• Le classifieur « Multiclass Decision Jungle » a trouvé pour des vins de qualités 7 :
o 1 % des vins analysés en qualité 4 : mauvaise prédiction
o 11,5 % des vins analysés en qualité 5 : mauvaise prédiction
o 44,2 % des vins analysés en qualité 6 : mauvaise prédiction
o 42,3 % des vins analysés en qualité 7 : bonne prédiction
o 1 % des vins analysés en qualité 8 : mauvaise prédiction
Il faudrait passer plus de temps à essayer d’autres classifieurs, ajuster leurs paramètres afin d’obtenir de meilleures prédictions. D’autres informations fournies dans la sortie du module Score Model peuvent faciliter l’analyse des données / résultats :
Remarque : Il est possible d’enregistrer le résultat d’un module dans un Dataset et donc de pouvoir le réutiliser comme entrée lors d’une expérimentation :
6 – Automatisation
Après avoir publié un Web Service, il peut être requêté de deux façons différentes : Mode requête -> réponse ou en mode Batch.
Le mode Batch permet l’upload d’un fichier dans un Azure Blob Storage. Celui ci contient les inputs, le Web Service traitera toutes les entrées du fichier et renverra un fichier en Output. Dans cet exemple je vais utiliser le mode Requête -> Réponse.
6.1 – Création de la table AML_Wine
Voici le script T-SQL de la création de la table AML_Wine :
CREATE TABLE [dbo].[AML_Wine]( [PK_ID] [INT] NOT NULL, [Quality] [NVARCHAR](50) NULL, [fixed acidity] [FLOAT] NULL, [volatile acidity] [FLOAT] NULL, [citric acid] [FLOAT] NULL, [residual sugar] [FLOAT] NULL, [chlorides] [FLOAT] NULL, [free sulfur dioxide] [FLOAT] NULL, [total sulfur dioxide] [FLOAT] NULL, [density] [FLOAT] NULL, [pH] [FLOAT] NULL, [sulphates] [FLOAT] NULL, [alcohol] [FLOAT] NULL, CONSTRAINT [PK_WINE] PRIMARY KEY CLUSTERED ([PK_ID] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
Insertion de vins pour lesquelles le Web Service devra prédire leurs qualités:
INSERT INTO [dbo].[AML_Wine]([PK_ID],[Quality],[fixed acidity],[volatile acidity],[citric acid],[residual sugar],[chlorides],[free sulfur dioxide],[total sulfur dioxide],[density],[pH],[sulphates],[alcohol]) VALUES (1,NULL,6.8,0.29,0.16,1.4,0.038,122.5,234.5,0.9922,3.15,0.47,10) ,(2,NULL,6.5,0.33,0.72,1.1,0.061,7,151,0.993,3.09,0.57,9.5) ,(3,NULL,6.4,0.24,0.29,11.4,0.051,32,166,0.9968,3.31,0.45,9.55) ,(4,NULL,7.1,0.26,0.34,14.4,0.067,35,189,0.9986,3.07,0.53,9.1) ,(5,NULL,5.9,0.24,0.26,12.3,0.053,34,134,0.9972,3.34,0.45,9.5)

Le package SSIS sera en charge d’actualiser la colonne Quality, les caractéristiques des vins seront transmises au Web Service qui prédira s’ils sont bons ou mauvais.
6.2 – Accès au Web Service
Voici les spécifications d’accès au Web Service :
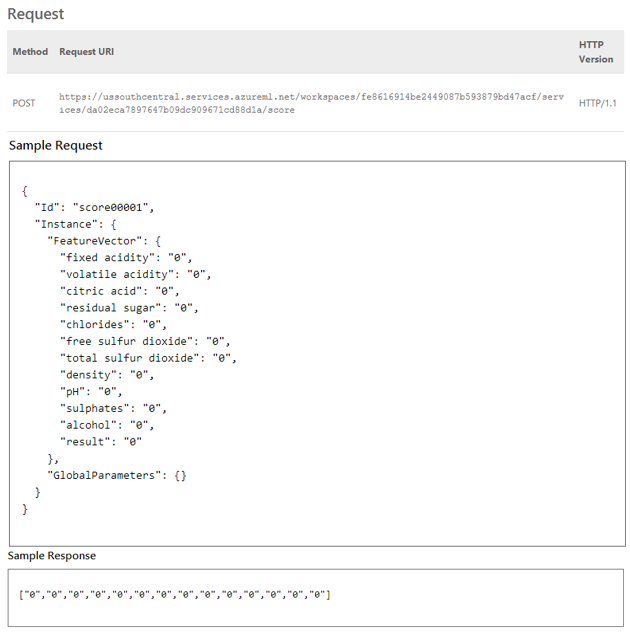
Code C# d’utilisation (N’oubliez pas d’inclure les références nécessaires) :
using System;
using System.Collections.Generic;
using System.IO;
using System.Net.Http;
using System.Net.Http.Formatting;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
namespace CallRequestResponseService
{
public class ScoreData
{
public Dictionary<string, string> FeatureVector { get; set; }
public Dictionary<string, string> GlobalParameters { get; set; }
}
public class ScoreRequest
{
public string Id { get; set; }
public ScoreData Instance { get; set; }
}
class Program
{
static void Main(string[] args)
{
InvokeRequestResponseService().Wait();
}
static async Task InvokeRequestResponseService()
{
using (var client = new HttpClient())
{
ScoreData scoreData = new ScoreData()
{
FeatureVector = new Dictionary<string, string>()
{
{ "fixed acidity", "0" },
{ "volatile acidity", "0" },
{ "citric acid", "0" },
{ "residual sugar", "0" },
{ "chlorides", "0" },
{ "free sulfur dioxide", "0" },
{ "total sulfur dioxide", "0" },
{ "density", "0" },
{ "pH", "0" },
{ "sulphates", "0" },
{ "alcohol", "0" },
{ "result", "0" },
},
GlobalParameters = new Dictionary<string, string>()
{
}
};
ScoreRequest scoreRequest = new ScoreRequest()
{
Id = "score00001",
Instance = scoreData
};
const string apiKey = "abc123"; // Replace this with the API key for the web service
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue( "Bearer", apiKey);
client.BaseAddress = new Uri("https://ussouthcentral.services.azureml.net/workspaces/fe8616914be2449087b593879bd47acf/services/da02eca7897647b09dc909671cd88d1a/score");
HttpResponseMessage response = await client.PostAsJsonAsync("", scoreRequest);
if (response.IsSuccessStatusCode)
{
string result = await response.Content.ReadAsStringAsync();
Console.WriteLine("Result: {0}", result);
}
else
{
Console.WriteLine("Failed with status code: {0}", response.StatusCode);
}
}
}
}
}
Remarque : Nous avons déjà testé ce mode d’accès pour le modèle de classification binaire.
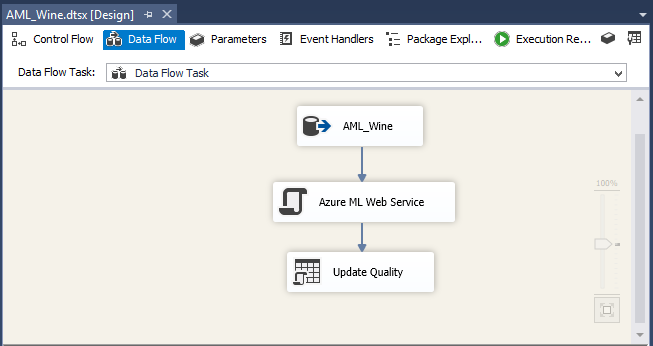
6.3 – Création du package SSIS
Le package SSIS est des plus simples, il lit la table AML_WINE,
la qualité des vins n’ayant pas encore été prédite, cette tache sera transmise au web service via un script C# qui enverra les caractéristiques des vins au Web Service. Celui-ci renverra la prédiction faite par le modèle. Enfin la dernière sera d’actualiser la colonne Quality (grâce à l’identifiant PK_ID) :
La partie la plus complexe se trouve au niveau de la tache de Script, la colonne Quality doit pouvoir être accessible en écriture afin d’actualiser la table AML_Wine :
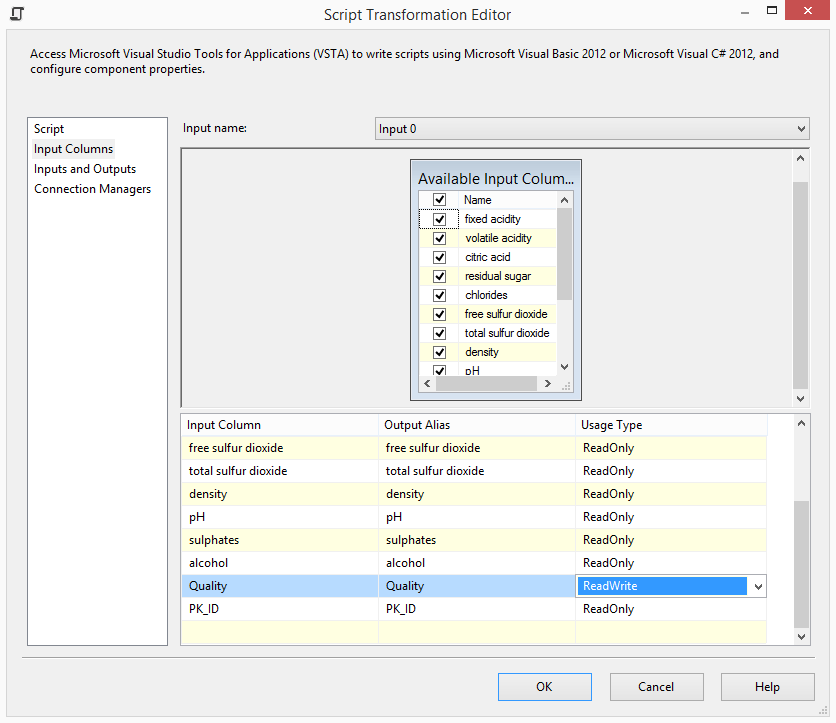
Les références suivantes doivent être présentes dans la solution :
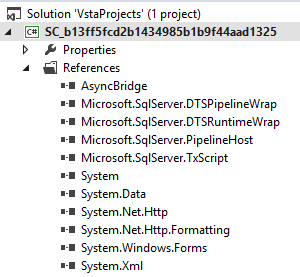
Chez moi le package Microsoft.Bcl.Async ne fonctionnait pas, j’ai dû installer le AsyncBridge.
Au passage quelques commandes Nuget bien utiles :
• Install-Package AsyncBridge
• Uninstall-Package AsyncBridge
Résultat :

7 – Conclusion
Dans cet article nous avons pu créer un modèle d’analyse prédictive permettant de prédire la qualité d’un vin en fonction de ses caractéristiques chimiques. Nous avons testé et benchmarqué plusieurs algorithmes permettant de répondre binairement (Bon ou Mauvais) et numériquement (de 0 à 10). Nous avons défini un point d’entrée et un point de sortie au modèle afin de pouvoir y accéder depuis l’extérieur via une API. Enfin nous avons automatisé l’analyse de nouveaux vins.
Cet exemple d’analyse prédictive laisse entrevoir de multiples nouveaux services, imaginez
que je puisse savoir si un vin est bon ou mauvais sans l’avoir testé et donc décider de l’acheter ou non… Je pourrais automatiser l’achat de vin…
En ayant peu de connaissances en Datamining j’ai réussi à créer un modèle d’analyse prédictif et à l’utiliser 🙂
Remarque : Il est aisé de créer un modèle avec Azure ML via des composants graphiques, mais maitriser toute la complexité des différents algorithmes, savoir lequel utiliser, savoir optimiser un modèle… Cela reste bel et bien un métier, celui de statisticiens, de data scientistes, …
Via Azure ML Microsoft offre une plateforme d’analyse prédictive dans le Cloud conçue pour les utilisateurs débutants ou expérimentés.
8 – Ressources
Voici quelques ressources sur Azure ML et le Machine Learning :
- Vidéo par Franck Mercier : http://blogs.technet.com/b/franmer/archive/2014/08/01/vid-233-o-azure-machine-learning.aspx
- Introduction par le projet Boticelli : https://projectbotticelli.com/knowledge/brief-introduction-to-microsoft-azure-ml
- Article écrit par Frédéric Gisbert : http://blogs.technet.com/b/sql/archive/2014/06/19/sql-server-chez-les-clients-self-service-bi-et-microsoft-azure-machine-learning.aspx
- Prise en main de l’outil par David Joubert : http://blog.cellenza.com/data/sql-server/microsoft-azure-machine-learning-premiere-prise-en-main/
- Microsoft Azure Machine Learning Release Notes : https://contosoafx.blob.core.windows.net/media/Release_Notes_MAML_PuP.pdf
- Tutorials videos : https://azure.microsoft.com/en-us/services/machine-learning/
- Azure ML Help : https://studio.azureml.net/Help/
- Blog Big Data France : http://blogs.msdn.com/b/big_data_france/
- Cour de Datamining : http://eric.univ-lyon2.fr/~ricco/cours/supports_data_mining.html

Salut,
Sur la présentation technique de la plateforme, l’article est très bien fait : didactique, bien centré sur les bases de la mise en place. Bref c’est une bonne entrée en matière et je n’ai pas trouvé d’article équivalent en français sur ces points (pour le moment).
Mais attention aux phrases réductrices du genre : « En ayant peu de connaissances en Datamining j’ai réussi à créer un modèle d’analyse prédictif et à l’utiliser 🙂 ». Avoir un modèle à utiliser c’est simple, même sur SAS on peut le faire et sans interface graphique ; mais avoir un bon modèle c’est complètement autre chose. Je peux te mettre entre les mains une guitare, tu vas savoir sortir des notes mais pas jouer un morceau car il y aura des concepts que tu ne maîtriseras pas. C’est la même chose ici. Arguer du fait que mettre à disposition une interface graphique agréable, des menus simples d’utilisation et vulgariser le vocabulaire permet de rendre abordable des concepts d’un domaine extrêmement technique, c’est se fourvoyer. Ce travail ne peut se faire sans notions avancées sur les statistiques, le datamining et les mathématiques. L’enrobage qu’en a fait Microsoft est d’une simplification révélatrice du fait que de plus en plus, nous cherchons à maîtriser les technologies sans en maîtriser les concepts. Pour appuyer ce dernier point, je mets au défi n’importe quel consultant décisionnel mettent en place un modèle sur Azur ML tout en étant capable de m’expliquer ce qu’est une régression linéaire (ils doivent se compter sur un doigt).
Salut Patrice ! En effet, il est aisé de créer un modèle avec Azure ML via des composants graphiques, mais maitriser toute la complexité des différents algorithmes, savoir lequel utiliser, savoir optimiser un modèle… Cela reste bel et bien un métier, celui de statisticiens, de data scientistes, …
Content de voir que tu partages mon point de vue (sinon j’aurai pu envoyer une milice venue des pays de l’est effectuer une visite de courtoisie ton appart’).
En parlant de ça, mon collègue de feu m’a dirigé vers ce site dont je suis en train de suivre les cours (ma copine me demande inlassablement de venir me coucher : je ne sais pas comment lui expliquer que je prends des cours sur des sujets… que j’ai boycottés à la fac). Et dans cette vidéo vers la fin, il fait une analogie assez proche de ce que je viens d’énoncer : https://class.coursera.org/ml-005/lecture/2
Pour celles et ceux que cela intéresse.
Héhé ! J’avais commencé ce cours avec mes amis de BigDataMonkeys.fr 😉 Il faudrait que je le finisse.
Patrice, tu m’as pris pour un Pokemon ? 🙂 Rendons à Monsieur Eiden ce qui lui appartient, étant donnée que c’est David et lui qui initialement m’ont parlé de ce cours, d’ailleurs on compte sur eux pour avoir le diplôme !
Great post. Had to translate it to english for me to understand, but very well written and explained. Thanks for taking the time to write this! 🙂
Thanks for your feedback Jason and sorry for didn’t translated already in English. I have to write more and more and English 😉
Merci Romain, excellent post. Je trouve que tu as bien illustré la mise en œuvre, de bout en bout, d’un modèle prédictif : de la récupération des données d’apprentissage jusqu’au déploiement du modèle sous forme de service.
Par contre, je pense qu’il faut faire attention à la phase de construction du modèle :
– Analyse des variables (explicatives vs expliquée – explicatives vs explicatives)
– Traitement des variables explicatives discrètes / qualitatives
– Traitement des valeurs manquantes / aberrantes ..
– Choix/sélection des variables explicatives et élimination des variables redondantes (peut-on utiliser des techniques comme le test de Khi2,… dans Microsoft ML)
– Choix des algorithmes potentiels
…
Je me demande si Microsoft a prévu tout ça et si oui comment ça pourrait être géré nativement ?
J’ai vu qu’on pourrait encapsuler du R donc théoriquement on pourrait résoudre toutes les problématiques « statistiques ».
Je me demande aussi où est ce qu’on pourrait trouver l’explication Mathématique/statistique des algorithmes proposés par Ms ?
Merci d’avance
Pingback: Petite introduction aux Big data : la machine à explorer les faits | archivEngines