Le flow de données généré par les médias sociaux ne cesse d’augmenter à tel point qu’il en devient difficile de les analyser. Pourtant, ces textes sont pour la plupart porteur d’opinion et les analyser permettrait à des entreprises de connaitre automatiquement l’image que les consommateurs ont de leur marque, de leurs produits, de leurs services, de leurs concurrents. Les personnalités politiques pourraient détecter des rumeurs ou anticiper des crises…
L’analyse des sentiments vise à déterminer l’opinion de l’auteur par rapport à un thème.

L’étude automatisée des sentiments n’est pas une nouvelle discipline, elle a été introduite par Sanjiv Das et Mike Che en 2001 afin d’analyser des sentiments dans le cadre de l’économie de marché. Plusieurs disciplines sont en jeux :
- Natural Language Processing (NLP) : discipline à la frontière de la linguistique, de l’informatique et de l’intelligence artificielle.
- Text mining et l’Opinion Mining : ensemble de traitements informatiques consistant à extraire des connaissances selon des critères de similarité dans des textes produits par des humains.
Déceler le sentiment d’une phrase n’est pas aisé, en effet il existe une infinité de variations et d’altérations linguistiques. Le sentiment dépend du contexte, de la personne, de sa langue, de son âge,… Les sous entendus sont difficiles à appréhender…
Il existe plusieurs techniques et algorithmes, comme la méthode de Classification naïve bayésienne qu’utilise NLTK un ensemble de bibliothèques Python permettant d’effectuer du machine learning pour classifier les sentiments.
Une autre approche consiste à utiliser une liste de mots où chaque mot a été catégorisé (positif / négatif). Il existe plusieurs dictionnaires comme AFINN et LabMT et sont pour la plupart en Anglais.
En 2012, pour une présentation aux Journées SQL Server 2012 j’avais utilisé Sentiment140, une API permettant d’obtenir le sentiment de Tweets : https://pulsweb.azurewebsites.net/jss2012-big-data-hadoop-bi/
Dans cet article je vais classifier des Tweets à l’aide d’un dictionnaire et utiliser la puissance de Hadoop pour traiter une grande volumétrie de données. Je me suis inspiré de plusieurs techniques et ai conçu cette approche qui n’est surement pas la plus précise, mais qui a le mérite d’être évolutive et qui dans un premier temps répond à mes besoins de catégorisations.
Le Principe
Le principe est simple, je vais :
- Fabriquer un dictionnaire de données et attribuer une note de 0 à 10 pour chacun des mots.
- Récupérer des Tweets au format JSON
- Creer un cluster HDInsight de 4 Noeuds.
- Sérialiser les Tweets avec des UDF Hive.
- Corréler et agréger les données via des requêtes HQL.
- Mettre en forme les résultats 🙂
Pour déterminer le sentimen t général d’un Tweet, il suffit d’ajouter les scores des mots trouvés dans le dictionnaire et d’en obtenir une moyenne.
t général d’un Tweet, il suffit d’ajouter les scores des mots trouvés dans le dictionnaire et d’en obtenir une moyenne.
Si la moyenne d’un Tweet est inférieure a 5 cela veut dire que le sentiment est négatif, s’il est égal a 5 le sentiment est neutre. Enfin si la moyenne est supérieure à 5 le sentiment sera positif.
Les Données
Voici le format d’un Tweet : https://dev.twitter.com/docs/platform-objects/tweets.
J’ai récupéré des Tweets et les ai sauvegardés dans un Blob Storage Azure (wasb://DATA@apvxdcube.blob.core.windows.net/tweets).
J’ai créé et uploadé le dictionnaire suivant au format TSV :
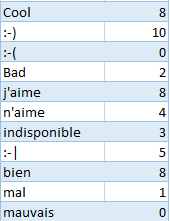
Hive
J’ai créé un cluster HDInsight de 4 noeuds en utilisant des commandes PowerShell : https://pulsweb.azurewebsites.net/hdinsight-powershell/
J’ai sérialisé les Tweets à l’aide de Hive Json Serde :
ADD jar C:\apps\json-serde-1.1.6-SNAPSHOT-jar-with-dependencies.jar;
CREATE EXTERNAL TABLE tweets (
id BIGINT,
created_at STRING,
source STRING,
favorited BOOLEAN,
retweet_count INT,
retweeted_status STRUCT<
text:STRING,
user:STRUCT<screen_name:string,name:string>>,
entities STRUCT<
urls:ARRAY<struct<expanded_url:string>>,
user_mentions:ARRAY<struct<screen_name:string,name:string>>,
hashtags:ARRAY>,
text STRING,
user STRUCT< screen_name:STRING, name:STRING, friends_count:INT, followers_count:INT, statuses_count:INT, verified:BOOLEAN, utc_offset:STRING, time_zone:STRING>,
in_reply_to_screen_name STRING
) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 'wasb://DATA@apvxdcube.blob.core.windows.net/tweets';
J’ai créé une table externe pour le dictionnaire
CREATE EXTERNAL TABLE dictionnaire (
word string,
polarity int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 'wasb://DATA@apvxdcube.blob.core.windows.net/dictionnaire';
J’ai créé trois vues :
CREATE VIEW view1 AS SELECT id, words FROM tweets LATERAL VIEW EXPLODE(SENTENCES(LOWER(text))) tmp AS words; CREATE VIEW view2 AS SELECT id, word FROM view1 LATERAL VIEW explode(words) tmp AS word ; CREATE VIEW view3 AS SELECT id, view2.word, d.polarity FROM view2 LEFT OUTER JOIN dictionnaire d ON LOWER(view2.word) = LOWER(d.word);
- view1 possède l’identifiant des tweets et un tableau contenant la liste de chacun des mots composant le tweet.
- view2 possède l’identifiant des tweets et ses mots qui le composent sur plusieurs lignes.
- view3 possède l’identifiant des tweets, ses mots et leurs polarités (de 0 à 10).
L’UDF sentences() découpe une phrase en un tableau de mot :
SELECT sentences(« Je m’appelle Romain Casteres ») FROM somedata LIMIT 1;
Résultat : [[« Je », »m’appelle », »Romain », »Casteres »]]
L’UDF explode() prend en entrée un tableau et renvoie les éléments du tableau sur plusieurs lignes.
J’ai créé une table interne :
CREATE TABLE sentiment
STORED AS ORC AS
SELECT
id,
CASE
WHEN AVG(polarity) > 5 then 'positive'
when AVG( polarity ) < 5 then 'negative'
ELSE 'neutral'
END AS sentiment
FROM view3
GROUP BY id;
J’ai créé une dernière table interne :
CREATE TABLE myResult STORED AS ORC AS SELECT t.*, s.sentiment FROM tweets t LEFT OUTER JOIN sentiment s ON t.id = s.id;
Les tables Hive internes créent sont stockées en ORC (Optimized Row Columnar), cela améliore les performances de Hive.
Résultat
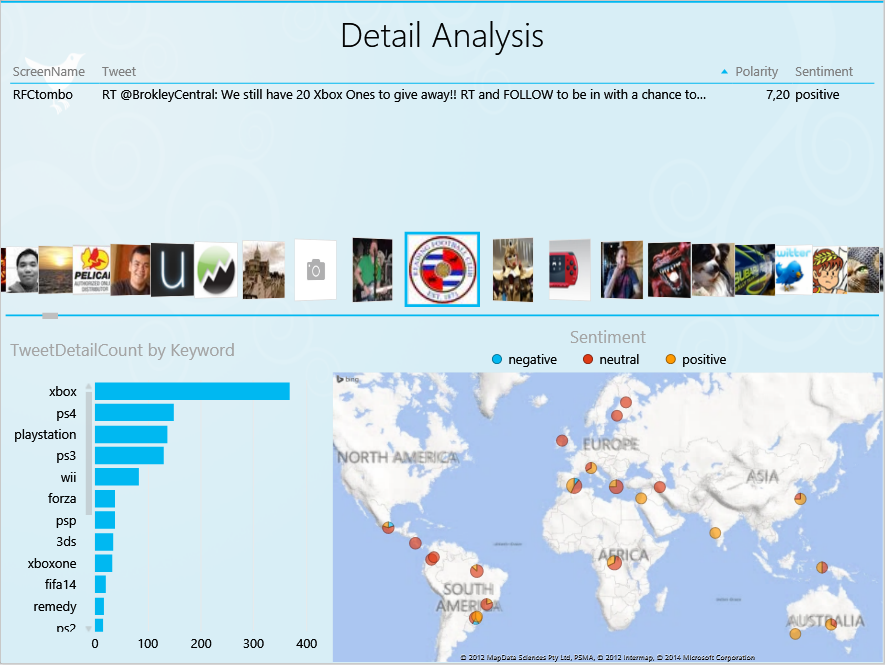
Ressources
- Seth Grimes : Articles
- Altaplana
- Sentiment Symposium
- Opinion mining et sentiment analysis
- Caddereputation
- Natural Language Processing Book
- Alchemyapi
- Google API

Comments are closed.