Apache Phoenix fournit une interface SQL au-dessus de l’architecture HBase. Dans cet article nous verrons comment utiliser Phoenix et installer l’interface SQuirreL sur un cluster HDInsight de type HBase dans Azure. Phoenix a été développé par les ingénieurs de Salesforce, depuis 2013 il fait partie de Apache Incubator.
![]()
Hive permet de maintenir et de gérer des données structurées dans Hadoop en fournissent un langage proche du SQL : HiveQL. Cependant Hive ne fournit pas des opérations au niveau des lignes telles que Insert, Update ou encore Delete.
HBase permet quant à lui des opérations au niveau des lignes. Il prend notamment en charge les commandes suivantes ‘SCAN’, ‘GET’, ‘PUT’, ‘LIST’ pour interroger les tables en entier, analyser une ligne, enregistrer une ligne ou énumérer les tables …
L’utilisation d’un langage comme le SQL facilite l’utilisation d’un outil, Hive en est la preuve. Phoenix fournit une couche SQL au-dessus de HBase et facilite ainsi son utilisation tout en apportant de nouvelles fonctionnalités.
HBase
![]()
HBase est un système de gestion de base de données non relationnelle distribué, écrit en Java, disposant d’un stockage structuré pour les grandes tables.
HBase elle est une base de données NoSQL orientée colonnes, elle est inspirée des publications de Google sur BigTable.
HBase est un sous-projet d’Hadoop, un Framework d’architecture distribuée. La base de données HBase s’installe généralement sur le système de fichiers HDFS d’Hadoop pour faciliter la distribution, même si ce n’est pas obligatoire.
HBase est proposé en tant que cluster HDInsight dans Azure, les données sont stockées dans un Blob Storage Azure (par défaut) ce qui fournit une faible latence et une élasticité (performances/coût).
Pour créer un cluster HDInsight de type HBase depuis le portail Azure :
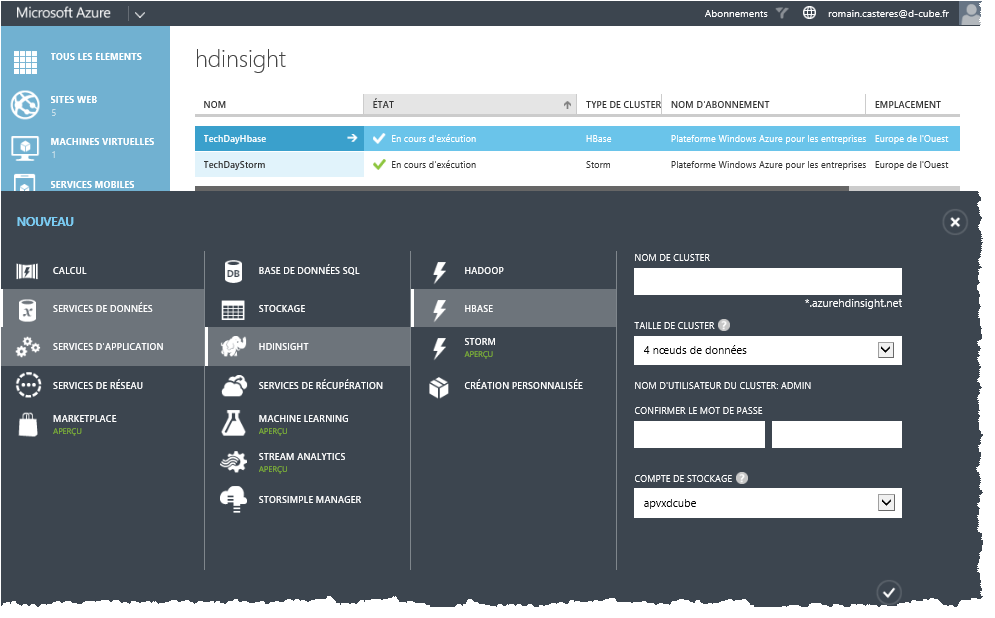
Quelques bases :
Après avoir activé l’accès distant et vous être connecté au cluster ouvrer l’interpréteur de commandes de Windows :
cd %hbase_home% bin\hbase shell
Quelques commandes :
-
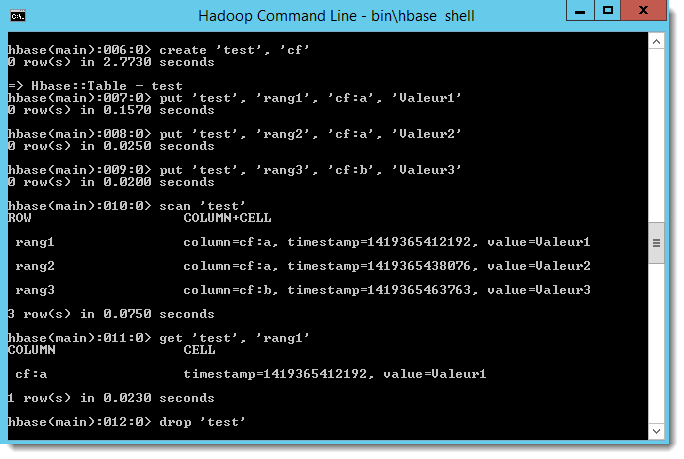
Liste des tables : > list
-
Création d’une table test : > create ‘test’, ‘cf’
-
Insertion dans une table test : > put ‘test’, ‘rang1’, ‘cf:a’, ‘Valeur1’
Insertion au rang1, de la valeur ‘Valeur1’ dans la colonne ‘a’ de la famille ‘cf’
> put ‘test’, ‘rang2’, ‘cf:a’, ‘Valeur2’
> put ‘test’, ‘rang3’, ‘cf:b’, ‘Valeur3’ -
Lecture d’une table : > scan ‘test’
-
Lecture d’une ligne d’une table : > get ‘test’, ‘rang1’
-
Désactivation d’une table : > disable ‘test’
Si vous voulez supprimer une table ou modifier ses paramètres, vous devez la désactiver avant. Vous pouvez le réactiver en utilisant la commande « enable ». -
Suppression d’une table : > drop ‘test’
-
Quitter HBase : > quit
Les colonnes dans HBase sont regroupées en familles de colonne, dans cet exemple ‘cf’ est la famille. Physiquement, tous les membres de la famille sont stockés dans un même système de fichiers.
– HBase est dit « SPARCE », les colonnes NULL ne sont pas stockées et n’occupent aucune place (// avec SQL Server l’option SPARCE sur les colonnes).
– Toutes les données sont stockées dans un tableau d’octets.
– Dans un Système de gestion de base de données relationnelle, pour obtenir par exemple toutes les données relatives à un utilisateur il faudra joindre les tables user, user_info et user_detail_info a l’aide de clés étrangère. Avec HBase il suffit de spécifier la famille de colonne de l’utilisateur pour obtenir les données relatives à celui-ci.
– Une bonne formation gratuite de Big Data University : Using HBase for Real-time Access to Your Big Data.
Phoenix
Apache Phoenix permet d’exécuter des requêtes SQL à faible latence sur HBase. Phoenix fournit un pilote JDBC et utilise des API HBase natives au lieu du modèle de programmation MapReduce.
Vous pouvez utiliser des clients JDBC standards comme SQuirreL pour vous connecter à Phoenix et ainsi interroger les données HBase ou via SQLLine, un utilitaire Java en mode console.
Lorsqu’une requête est transmise à Phoenix, le moteur transforme la requête en un ou plusieurs scans HBase. Le moteur de requête exécute les scans en parallèle pour produire un ensemble de résultats sous forme de tableau. Phoenix utilise l’API HBase, le coprocesseur HBase et des filtres personnalisés pour optimiser les performances des requêtes.
Phoenix vs Hive (running over HDFS and HBase) :
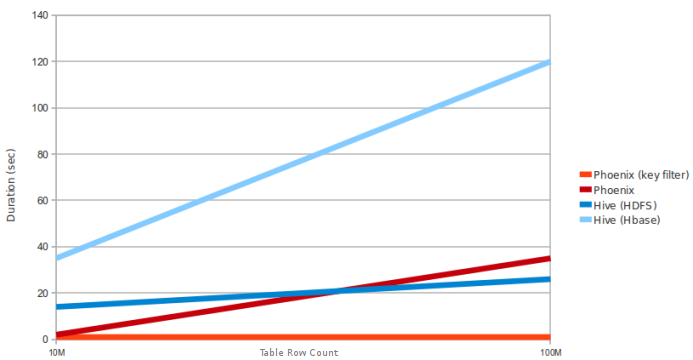
Requête : select count(1) from table over 10M and 100M rows. Data is 5 narrow columns. Number of Region Servers: 4 (HBase heap: 10GB, Processor: 6 cores @ 3.3GHz Xeon)
Voici où se situe Phoenix dans l’écosystème Hadoop :
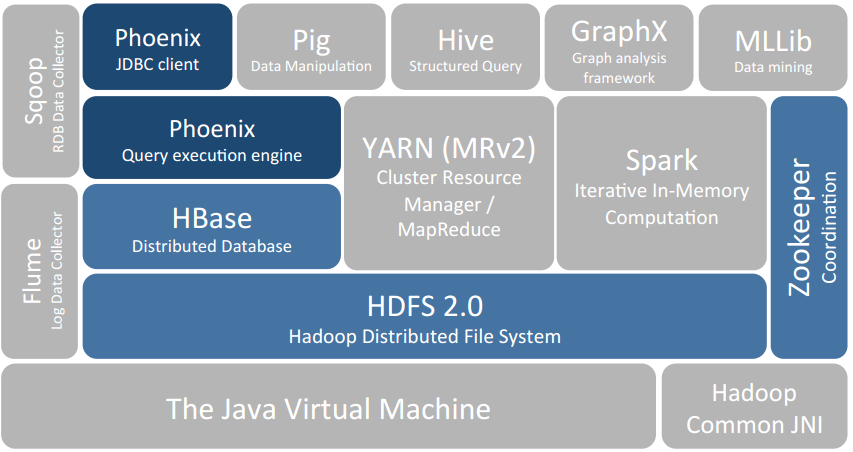
SQLLine
Pour vous connecter à Phoenix, il vous faut spécifier le nœud du cluster HBase pour lancer l’interface de commande SQL, exécutez la commande suivante depuis le répertoire Bin du dossier d’installation de Phoenix (C:\apps\dist\phoenix-4.0.0.2.1.9.0-2196\bin) :
> sqlline.py zookeeper2.###.##.internal.cloudapp.net
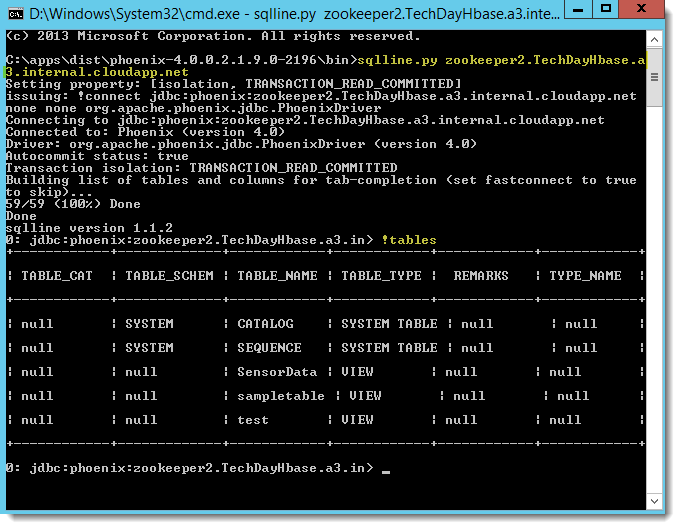
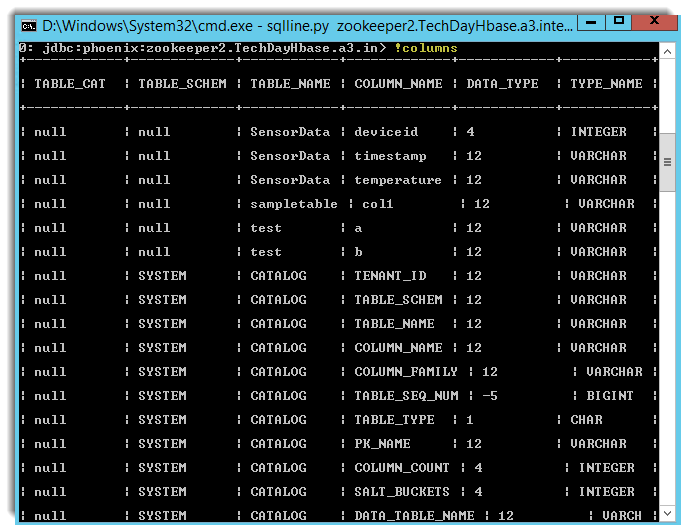
Pour quitter SQLLine : Ctrl + D.
SQuirreL

SQuirreL SQL Client est un programme permettant de visualiser la structure d’une base de données compatible JDBC, de parcourir les données et d’exécuter des commandes SQL, …
Pour télécharger SQuirrel : Install jar of SQuirreL 3.6 for Windows/Linux/others
Après avoir téléchargé SQuirrel, copier le .Jar dans un répertoire du cluster et installer le :
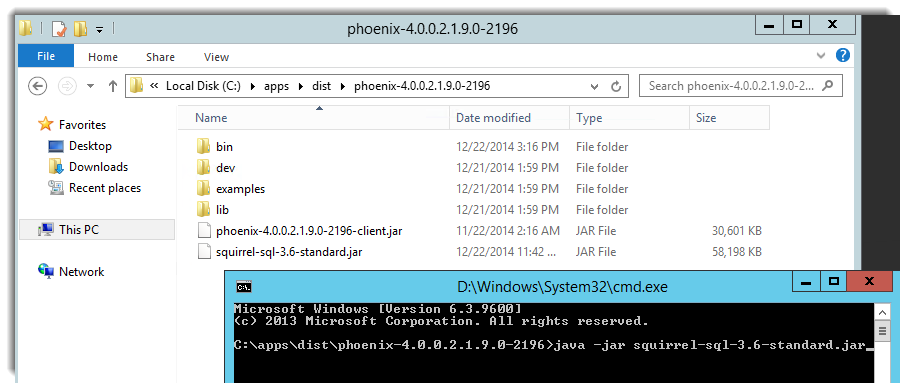
Une fois installé, copier le fichier « phoenix-4.0.0.2.1.9.0-2196-client.jar » dans le dossier « lib » du répertoire d’installation de SQuirrel. Ajouter un nouveau Driver « Hbase » de class « org.apache.phoenix.jdbc.PhoenixDriver » et insérer l’adresse de votre cluster « jdbc:phoenix:zookeeper2.###.##.internal.cloudapp.net ».
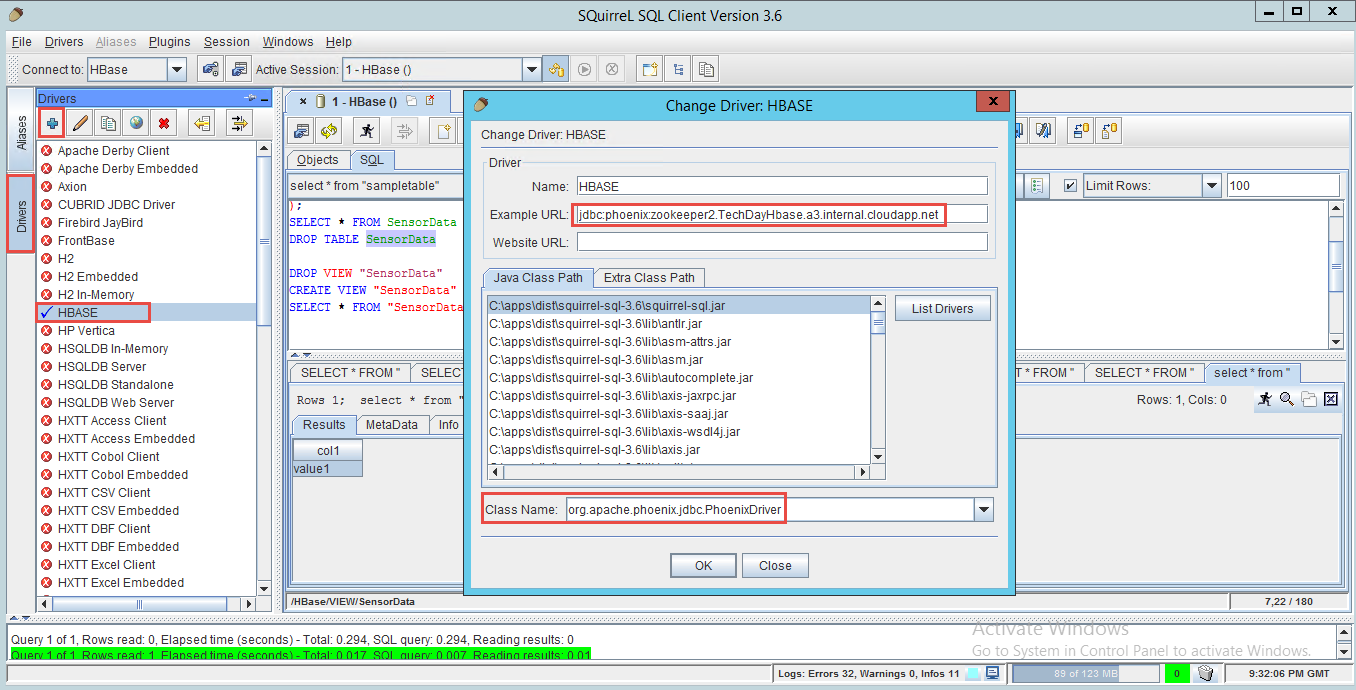
Pour connaitre l’adresse de votre cluster HBase, accéder à l’adresse suivante depuis celui-ci : http://zookeeper0:60010/master-status
Il est possible de créer des vues au-dessus de tables HBase :
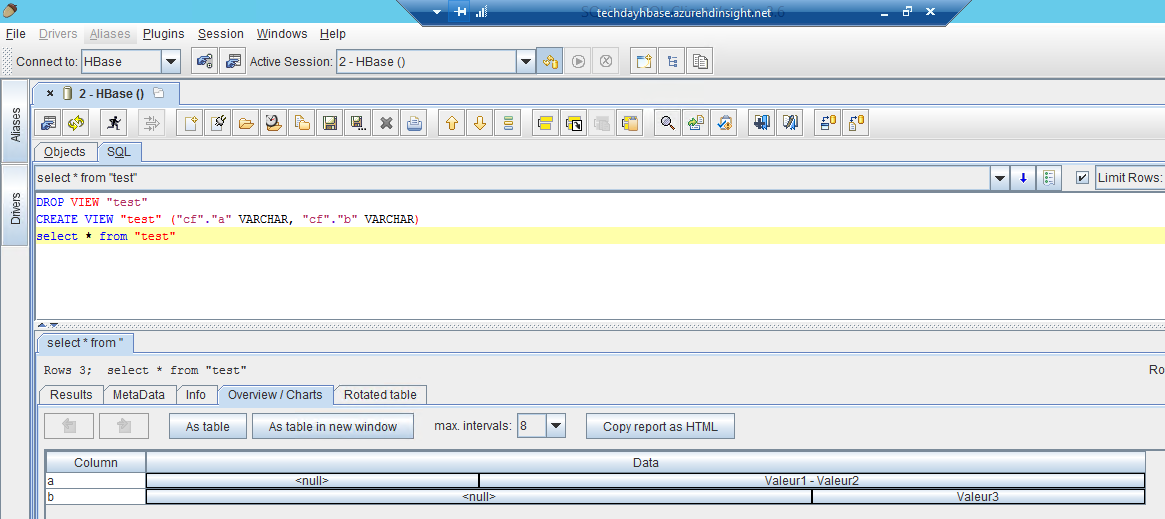
Remarque : les doubles quotes permettent de garder la caste, autrement les objets créés depuis Phoenix seront tous en majuscule.
Ressources
- Phoenix overview: http://phoenix-hbase.blogspot.fr/2014/01/our-move-to-apache-is-now-complete.html
- SQuirreL informations : http://squirrel-sql.sourceforge.net/
- Phoenix wiki: https://github.com/forcedotcom/phoenix/wiki
- Phoenix SQL language reference: http://forcedotcom.github.io/phoenix/
- Phoenix performance: https://github.com/forcedotcom/phoenix/wiki/Performance#phoenix-vs-related-products
- User group: https://groups.google.com/group/phoenix-hbase-user

I can’t get SQuirreL to work unless I put the cluster and a DNS VM in a vnet.