Du 17 Juin au 21 Juin 2013 j’étais à Londres pour une formation avancé de 3 jours sur SSAS avec Christopher Webb 🙂
Cette formation s’adresse aux développeurs SSAS de niveau intermédiaires – expérimentés souhaitant optimiser et concevoir des cubes multidimensionnels avancés.
Nous étions une dizaine « d’étudiants » en provenance d’Europe et de métiers assez différents (CIO, DSI, Développeur…)
J’ai beaucoup appris et conforté mes connaissances. La formation est ponctuée de cas concrets rencontrés par Chris lors de missions ce qui la rend super intéressante ! Petite déception le MDX a été abordé qu’à la fin et pas dans le détail 🙁 (Une autre formation lui est dédiée : http://www.technitrain.com/coursedetail.php?c=22)
La formation
Je ne pourrais en aucun cas résumer dans un article la formation ! J’ai cependant essayé d’après mes notes de créer un mini référentiel de bonnes pratiques.
1er Jour :
- À ton besoin d’un entrepôt de données (DWH) ? Oui il faut un DWH en amont d’un cube (Historisation, multiple source…) et il est préférable de le développer en même temps, car il est parfois nécessaire de modifier le DWH pour le besoin du cube. Plus généralement il est conseillé d’utiliser les règles de Ralph Kimball.
- Schémas en étoile vs Schémas en flocon ? Il est préférable d’éviter les schémas en flocon pour faciliter la création des dimensions et empêcher SSAS de générer des jointures (augmentation du temps de Processing).
- Natural vs Surrogate Keys ? • Il est préconisé par Kimball d’utiliser des clefs de substitution plutôt que des clefs naturelles (basées sur les données réelles) cela pour la gestion des Slowly-Changing Dimensions et d’autres… Pour la dimension temps, il est toutefois recommandé d’utiliser une clef naturelle comme « 20130722 ».
- ETL vs Views vs DSVs ? Il est parfois tentant de modifier la DSV depuis SSAS, mais c’est à éviter ! Contourner l’ETL et utiliser des Named Queries alourdissent les temps de Processing, il est préférable de créer des vues dans le modèle cela facilitera la maintenabilité de la solution et l’analyse d’impact (en cas de modification).
- Plus généralement : • Ne vous connectez pas au cube en mode Live (SSAS Online Mode) pour effectuer des modifications, c’est dangereux !
• Les clefs primaires doivent être de types de données compacts, tels que des entiers (smallint par exemple).
• Les colonnes de clefs étrangères du DWH ne devraient jamais être NULLABLE.
• Ignorer les erreurs de clef pendant le traitement du cube conduira à des données erronées.
• Il est préférable pour éviter les Key Errors et les Unknown Members d’utiliser l’ETL pour gérer l’intégrité de votre DWH.
• Il n’est pas déconseillé de désactiver les clefs étrangères du DWH en Production pour accélérer les traitements d’intégrations.
• Utiliser un outil de suivi de source tel que TFS.
• N’hésitez pas à utiliser BidsHelper : http://bidshelper.codeplex.com
• Lors de la création de dimension, il est préférable de changer les Attribute Name dès le début. En effet leur ID immuable est défini pour la première fois avec son Atribute Name.
• Les Parent / Child Hierarchies sont à éviter (si possible).
Nous avons fini ce premier jour de formation par une longue discussion sur les qualités / défauts d’un gros cube vs plusieurs petits cubes, en gros : Ca dépend !
2eme Jour :
- Distincts Counts Les Distincts Counts Measures sont créées dans leurs propres groupes de mesures et ça n’est pas pour rien. En effet elles sont plus lentes que d’autres mesures et exigent une stratégie de partitionnement spécial. Elles sont friandes d’IO ! L’utilisation de SSD (Solid State Disks) peut être utile . Il est possible via quelques manipulations de les intégrer dans des groupes de mesures existants (pur souci d’esthétisme dans Excel).
- Account Aggregation Je ne connaissais pas l’agrégation par « Account ». Elle permet de créer des mesures qui ont un comportement semi-additif différent suivant les membres. Elle est généralement utilisée dans des applications financières.
- Déploiement Déployé des changements à une base de données de production directement depuis BIDS est dangereux ! Il est préférable d’utiliser l’assistant de déploiement.
- Partitionnement Le partitionnement d’un groupe de mesures vous permet de retraiter seulement les partitions où il y a de nouvelles données / des données modifiées. Généralement le partitionnement s’effectue suivant la dimension temps. Il peut être intéressant d’utiliser un package SSIS pour créer, supprimer ou encore traiter les partitions SSAS.
- Plus généralement : • Il est préférable de traiter le cube par Schedule plutôt que de mettre en place une mise en cache proactive.
Récemment un client m’a demandé cela, et malgré mes alertes…
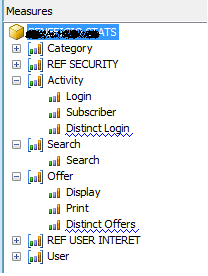
Notez que BIDS nous indique par un soulignement un Warning : « Break distinct count measures into separate measure groups. »
• L’utilisation de SSAS Database Syncrhonize peut être très intéressante pour rafraichir une base (Online).
3eme Jour :
J’attendais avec impatience cette journée, au programme : Architecture de SSAS et Optimisation de cube !
- Plan d’exécution : SSAS est constitué de deux moteurs • Formula Engine : c’est un mono-thread, il détermine qu’elles sont les données nécessaires pour répondre aux besoins. Il fait l’essentiel du travail d’analyse en limitant grâce aux cellules en mémoire les données à interroger au Storage Engine.
- Querry Tunning Il faut dans un premier temps avoir un point de référence, mais aussi :
- Profiler : De plus en plus d’événements sont disponibles dans le Profiler concernant SSAS Voici une liste d’événements intéressants a suivre :
- Cache-Warmer Cache-Warmer est une technique permettant de précacher les données du cube. Il est intéressant de l’automatiser via des packages SSIS. Deux bons articles sur le sujet : SQLIs et CWebbBI
- MDX • Éviter le MDX est une bonne chose !
- Plus généralement : • L’agrégation est LE levier d’optimisation d’un cube
• Storage Engine : c’est un multi-thread, il récupère les données demandées par le Formula Engine. L’utilisation de SSD ou la conservation des données en mémoire permettent d’accélérer les requêtes.
Lors de l’exécution le Formula Engine créer des Subcubs (tranches de données du cube définit pour une granularité) et envoie au Storage Engine la requête. Le Storage Engine vérifie si les données sont en cache, sinon il ira les lire sur le disque (ce qui est plus long). Il va vérifier s’il peut obtenir les données à partir d’une agrégation existante, s’il ne peut pas il va descendre jusqu’à la granularité la plus fine pour les agrégés (utilisation de la CPU).
Un bon article de Chris : Ici.
• S’assurer que personne d’autre n’utilise le serveur
• Se connecter a l’environnement de Production ou un backup de celui-ci
• Vider le cache
• Exécuter la requête et mesurer la durée, pour obtenir les performances du cache à froid
• Exécuter la requête à nouveau pour obtenir les performances du cache à chaud
– Query Begin
– Query End
– Execute MDX Script Begin
– Execute MDX Script End
– Query Cube Begin
– Query Cube End
– Calculation Evaluation
– Query Subcube Verbose
– Progress Report Begin / End : to see storage engine reading data
– Get Data From Aggregation
– Get Data From Cache (trop d’info)
– Ressource Usage : number of read pour une query particulière
• L’ordre des appels peut impacter les performances (Measure1 appelle Measure2)
• Retourner la valeur NULL quand vous pouvez (Exemple avec le IIF avant une division)
• Formatmdx : Un petit outil en ligne vous permettant de mettre en forme votre code MDX
• PréAggrégé toutes vos données n’est pas une solution !
• L’optimisation des agrégations suivant l’usage est très efficace
• Analysis Services Stored Procedure Project : http://asstoredprocedures.codeplex.com/

Déjà la fin !
Ma formation à Londres s’est finie en musique puisqu’après avoir rencontré une CouchSurfeuse d’Argentine nous sommes allés à un Crawl Bar histoire de découvrir Londres de nuit 😉
Je tiens à remercier Chris Webb pour cette super formation, l’ambiance était studieuse et les conditions excellentes. Enfin merci à ma société Dcube pour m’avoir permis d’y assister.
Salut Romain,
Très bon article rappelant les fondamentaux de design dwh/ssas.
Au passage, j’ai bien aimé les paragraphes :
– Etoile Vs Flocon : et oui les flocons sont à éviter, on ne le répétera jamais assez
– Natural Vs Surrogate Keys : il faut vraiment insister sur ces principes de modélisation qui ne sont pas toujours respectées
– ETLS Vs View Vs DSV : tiens çà me rappelle un article çà 😉
Pour les parent/child hierachies, j’ajouterai qu’il est toujours préférable de les aplatir (tous comme les flocons) surtout si la profondeur est connue (c’est marrant mais il n’y a pas d’autres façon de le faire en Tabular); l’utilisation des vues est à mon sens de bonne augure dans ce cas (via une CTE par exemple).
Concernant les Distinct Count, je comprends le point de vue des utilisateurs, le fait d’avoir un groupe de mesure dès qu’on déclare une mesure de ce type ne fait que « complexifier » le modèle exposé. Mais il ne faut en aucun cas supprimer ces groupes de mesures alors comment respecter les bonnes pratiques tout en répondant aux attentes utilisateurs : tout simplement en masquant les mesures DistinctCount et en les utilisant via des mesures calculées rattachées aux « bons » groupes.
@+
Fred.
Thanks for your kind words Romain, I’m glad you enjoyed it!